

Overcoming the Most Common Apache Spark Challenges: Proven Strategies and Solutions
Spark
5 MIN READ
July 19, 2024
![]()

When we talk about today’s data-driven world, managing a massive amount of data is essential for business success to stay ahead in this competitive world. Here comes Apache Spark which is considered an emerging Big data processing framework that offers scalability, speed, and versatility.
Many users have questions that: Is Apache Spark Enough to Make Better Decisions?
The simple answer to this question is Yes.
Apache Spark is a well-known word in the big data world. A powerful software that is 100 times faster than any other platform. It might be fantastic but it comes with a lot more challenges.
In this article, we are going to discuss the entire journey of Big data challenges and how you can overcome them. Learn about strategies and how Ksolves consulting solution works on handling the datasets to optimize the Spark jobs for peak performance that has been encountered in real-time data scenarios.
Also Read: Is Apache Spark enough to help you make great decisions?
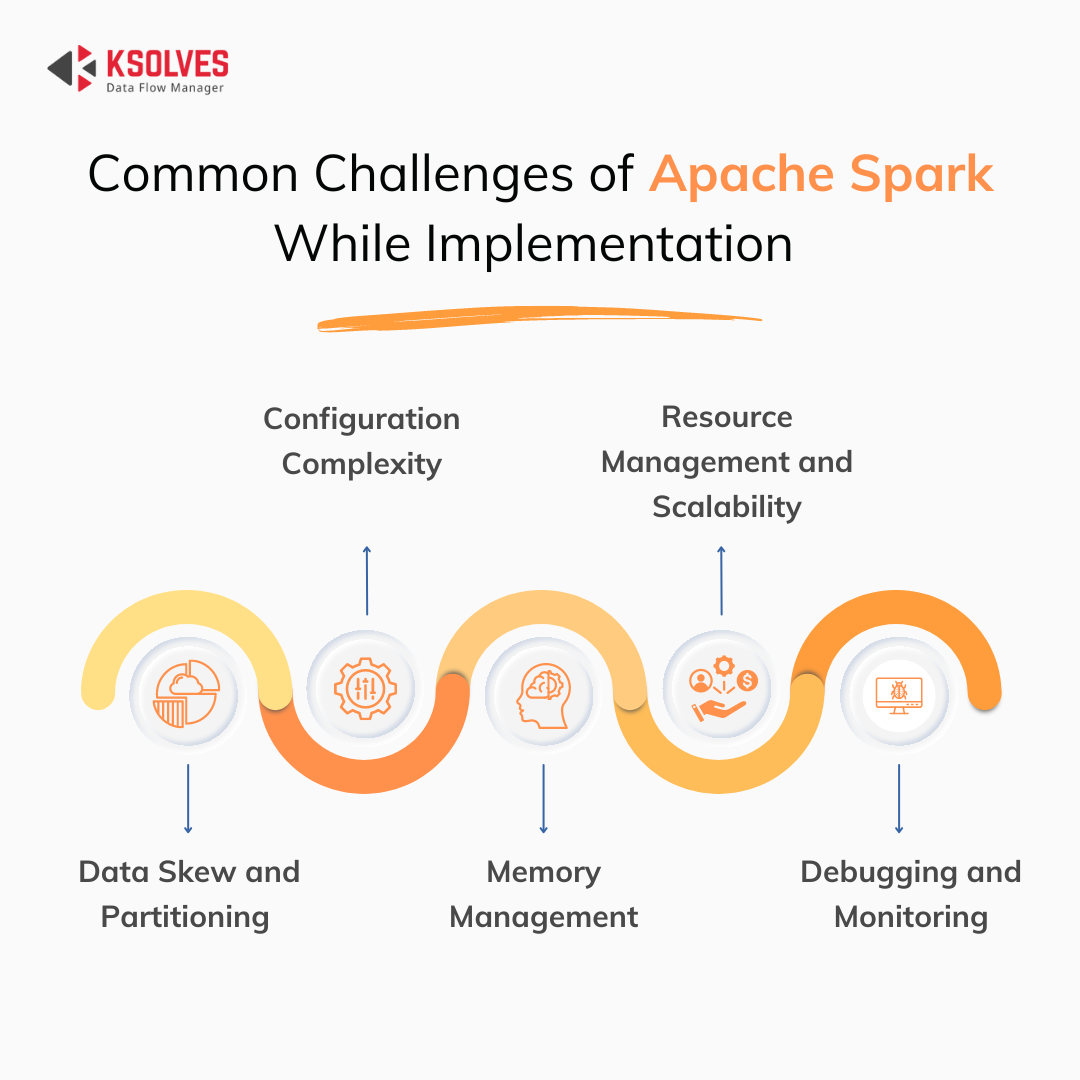
Top Apache Spark Challenges While Implementation
-
Configuration Complexity
Apache Spark has a wide range of configuration options for managing multiple resources like memory, executors, and tasks.
However, it is difficult for users to work on the proper settings as they impact each other and also lead to slow jobs or resource consumption issues if not managed properly.
In addition, no solution fits with organizations of all sizes. The proper configuration of Apache Spark depends on the specific spark job requirements including the data size and other business operations involved.
The difficulty in configuring the Apache Spark for some specific workloads needs a lot more understanding of the entire architecture. Even the nature of the Apache spark data created and being processed makes it challenging for consumers without experience.
-
Resource Management and Scalability
Managing the multiple resources present in the Apache Spark cluster is quite complex when we talk about the amount of data and the number of users present in the organization. To make use of resources properly, it is necessary to have careful planning.
Additionally, resource management in Spark must be balanced properly when running in the same cluster mode against third-party applications. Multiple scalability issues arise when the transition is done from small-scale development to large-scale production which showcases the need for cluster management tools and strategies.
-
Data Skew and Partitioning
Data Skew comes as another Apache Spark challenge arises while partitioning the data that is larger than the other data and directly impacting the performance of Spark jobs. When distributing unequal data across multiple partitions, will lead to some tasks that take much time, cause time delays, and affect the proper use of resources.
Proper partitioning of the data is crucial for balancing the load distribution but achieving this is quite complex especially when it comes to heterogeneous data sets. It is important to identify the data skew challenge that requires a deep analysis and needs tailored solutions.
-
Memory Management
Apache Spark completely depends on in-memory processing that helps to achieve better performance but this makes memory management a critical challenge. Insufficient allocation of memory leads to garbage collection, failure of tasks, and out-of-memory errors.
Balancing the use of memory between various components of Apache Spark such as driver, executors, and storage needs careful tuning and monitoring. Understanding and managing the use of memory consumption is important for maintaining the scalability of Spark applications.
-
Debugging and Monitoring
Monitoring the entire Apache Spark application architecture comes as a major challenge because of its distributed nature. When multiple errors and performance issues occur across different nodes and stages of a job, it makes it difficult to point things properly.
However, there are multiple comprehensive tools present in Spark that track the performance metrics, analyze the bottlenecks, and diagnose the business problems. But setting up and utilizing them properly often required a lot more business expertise.
Hence, the above-mentioned challenges focus on Spark’s complexity of maintaining it in a productive environment. It also requires skilled professionals and robust tools to manage the multiple conditions effectively.
Must Read: Apache Spark Best Practices for Data Science
Solution to Overcome Apache Spark Challenges
-
Serialization is Key
Serialization is very important during the performance of distributed applications. Those formats that are slow to serialize objects, and also those that consume large bytes will automatically slow down the computation.
The issue here is that you’ll have to distribute codes for running and the data needs to be executed. Thus you need to make sure that your programs can serialize, deserialize, and send objects across the wire. This is probably the first thing that you need to tune to optimize a Spark application. We also recommend you use the Kryo serializer, as the Java serializer gives a mediocre performance.
-
Getting Partition Recommendations and Sizing
Any performance management software that sees data skew will refer to more partitions. Let that fact sink in that the more partitions you have, the better your serialization will be.
The perfect way to decide the number of partitions in an RDD is to equate the number of partitions to the number of crores in the cluster. We do this so that the partitions will process in parallel and the resources receive optimal utilization. We recommend you avoid any situation where you have four executors and five partitions.
-
Monitoring Executor Size and Yarn Memory Overhead
Apache Spark developers often try to subdivide data sets into the smallest pieces that can be easily consumed by Spark executors, but they don’t want them to be extremely small. Well, there are some ways through which you can find a middle ground, and one needs to find a solution for data skew by ensuring a well-distributed keyspace.
You should make a rough guess at the size of the executor based on the data amount you want to be processed at a single time. There are two values in spark on YARN to track the size of the executor, and the YARN memory overhead. Well, this function is to prevent the YARN scheduler from killing any application that uses huge amounts of data from NIO memory.
-
Utilizing the Full Potential of DAG Management
It is always better to track the complexity of the executive plan. DAG is the directed acyclic graph visualization tool and comes with a SparkUI for one visual map. If Apache Spark developers think that something that should be straightforward is taking 10 long stages, they can look at their code and reduce it to two to three stages.
We suggest you look at all the stages in parallelization. Track the DAG and don’t focus just on the overall complexity. You need to make sure that the code you have is running in parallel. If you find that you have a non-parallel stage that uses less than 60% of the unavailable executors, you should keep in mind some questions-
- Should that computer be rolled into other stages?
- Is there any issue with separate partitioning?
-
Managing Library Conflicts
In terms of shading, we recommend you ensure that any external dependency classes are available in the environment that you are using, and also they do not conflict with the internal libraries used by Spark. One such example is Google Protobuf, which is a popular binary format for storing data that is more compact than JSON.
Benefits of Apache Spark For Business Excellence
-
Real-Time Processing
Apache Spark is considered a dynamic approach that focuses on real-time data processing and allows businesses to analyze the generated data. It can provide real-time insights and is used for multiple industries including Finance, healthcare, and E-Commerce. This will automatically improve the customer experience, reduce errors, and lead to a decision-making process.
-
Platform Scalability
Platform Scalability is another major benefit of Apache Spark that is utilized to scale businesses. When it comes to handling massive amounts of data, Spark’s distributed computing framework makes sure that all the workloads are balanced to optimize the performance and perform the right utilization of resources. Spark’s scalability helps businesses achieve rapid growth without facing any major issues.
-
Pre-Built Integrators
Apache Spark offers a range of pre-built integrators that focus on instant migration with other data processing tools and storage systems. Spark’s integrators manage the process of setting up the data pipelines that reduce the time and complexity of business development.
-
Batch Processing
When we talk about real-time processing for getting instant business insights, batch processing works as an important part of handling massive amounts of data. It also provides robust batch-processing capabilities that allow enterprises to perform large-scale business transformations, and generate comprehensive reports.
-
Event Sourcing
Event sourcing is a standout feature of Spark that makes sure all the changes in the application are stored in proper events. It works effectively and allows businesses to maintain an accurate, immutable record of all events within their systems. This is also beneficial for industries that require audit trails such as finance and legal for maintaining data consistency.
Why Do You Need Ksolves Apache Spark Consulting Services?

After discussing all the above-mentioned challenges and their solution, there are multiple things in the row. Even while utilizing Apache Spark individually, you need a lot more expertise.
Well, when we come to the decision, we realize that there is no better thing than Apache Spark Consulting Services. Our customized approach works on providing the best solution with budget-friendly plans.
Ksolves has an experienced team of Apache Spark developers who have expertise in handling a large number of teams and providing you with fault-free services. To know more about this, you can connect with Ksolves experts or directly email sales@ksolves.com.
Conclusion
Hence, we understand how leveraging the use of Apache Spark with its potential helps organizations to solve the complexities of Spark implementation. This big data framework is essential to adopting effective strategies such as optimizing serialization, ensuring the proper partitioning, monitoring the executor size, utilizing DAG management, and managing multiple library conflicts.
By opting for Ksolves Spark Consulting Services, businesses can explore its power to drive data-driven success and maintain a competitive advantage to stay ahead in the market.
![]()















AUTHOR
Spark
Atul Khanduri, a seasoned Associate Technical Head at Ksolves India Ltd., has 12+ years of expertise in Big Data, Data Engineering, and DevOps. Skilled in Java, Python, Kubernetes, and cloud platforms (AWS, Azure, GCP), he specializes in scalable data solutions and enterprise architectures.
Share with