

Continuous Integration / Continous Delivery of Pipelines
Machine Learning
5 MIN READ
February 23, 2023
![]()

In this setup, we are introducing a system to thoroughly test pipeline components before they are packaged and ready to deploy. This ensures continuous integration of pipeline code as well as continuous pipeline delivery, an important component of the automation process that was not present in the previous setup (continuous model delivery).
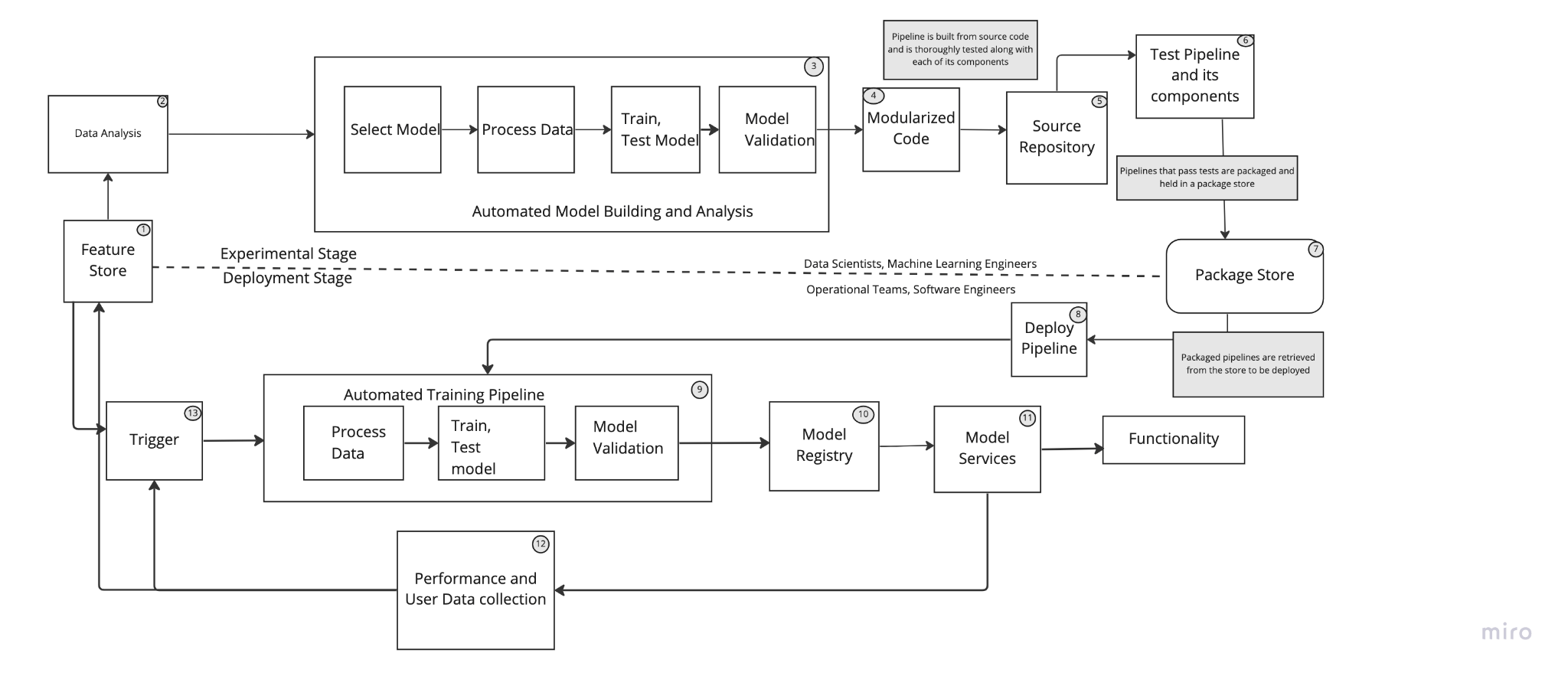
Figure depicts introducing testing systems and a package store to the new automation setup
Though this is mostly the same setup explained in the previous blog, keeping in mind the emphasis on the newly introduced elements.
- Feature Store: It contains standardized data processed into features. These features can be pulled by ML Engineers/Data Scientists for offline data analysis. Upon activating the trigger, these features can also be pulled into the automated training pipeline to further train the deployed model.
- Data Analysis: This step is usually performed by the ML Engineers/Data Scientists on features pulled from the feature store defined in previous step. The results of this analysis can help determine whether or not to develop a new model or tweak the architecture of the existing model and retrain it from there.
- Automated model building and analysis: This crucial step is performed by the model development team. Models are developed by the team and passed into the pipeline with the fair assumption that they are compatible with training, testing, and validation code. The entire process is automatically conducted with a model analysis report generated at the end. In another scenario where teams want to develop the latest ML architectures, models have to be developed from scratch with integration into the pipeline in order to maintain modularity. Some parts of the pipeline code also have to change, which is acceptable as new components of this setup can handle this automatically.
- Modularized Code: Once the developed model reaches a minimal level of performance in the validation step, the pipeline along with its components, and the model are all ready to be modularized and stored in the source repository.
- Source repository: This repository contains all the packaged pipelines as well as model codes for different pipelines and different models. In the previous setup (continuous model delivery), pipelines and models would be pulled from here, manually integrated, and deployed by software engineering teams. In this setup, the modularized code must now be tested in order to make sure all components are working correctly.
- Testing: This is an important setup to achieve continuous integration. Pipelines along with their components, including the model must be tested to ensure all correct outputs. Additionally, the pipelines themselves must be tested so as to be sure that they are guaranteed to work with the applications and how they are designed. The application is developed/programmed in such a way that a specific behaviour from the pipeline is expected, and the pipeline must behave correspondingly.
With pipelines and ML models, some testing examples include:
- Does the validation testing procedure lead to the correct tuning of the hyper-parameters?
- Is the data processing performed correctly?
- Does the data processing component correctly perform data scaling and feature engineering?
- Does the model analysis work correctly?
If the model truly performs well as expected but faults in the model analysis component of the pipeline lead the data scientists/ML engineers to observe that the model is not performing as expected, this could probably lead to issues where deployment of the pipeline is slowed down.
- Package Store: This can be considered as the containment unit that can hold various package pipelines. This step is optional but is taken into consideration so that there is a centralized area where every contributing team can access packaged pipelines that are deployment ready. Model development team can push this package store, and software engineers and operational teams can retrieve a packaged pipeline and deploy it. In that sense, it is similar to model registry; through this, both help in achieving continuous delivery.
- Deploy Pipeline: Pipelines can be retrieved from the package store explained earlier and deployed in this step. Contributing teams usually want to deploy the pipelines into a test environment where it is usually subjected to further automated testing to ensure full compatibility with all applications.
- Automated training pipeline: The automated training pipeline developed before, once deployed, exists to further train models when triggers are to be activated. This keeps models updated as possible on new trends in data and helps in maintaining high performance for longer time. Upon validation of the model, models are again sent to the model registry where they are kept until they are required for any services.
- Model Registry: The Model registry basically holds trained models until they are needed for their services. Once again, continuous delivery of model services is achieved as the automated training pipeline continuously provides model registry with high performance ML models that are to be used to perform various other services.
- Model Services: The best models as per the application use case are pulled from the model registry to perform the required application services.
- Performance and user data collection: Model performance data (business metrics) and user data are collected to be sent to the model development teams as well as to the feature score respectively. Teams can then use these business metrics for the respective model to decide what next course of action has to be taken.
- Training Pipeline Trigger: This involves some conditions being met (it refers to previous setup i.e. continuous model delivery) to initiate the re-training of the deployed pipeline and feed it with new features that are being pulled from the feature store.
Reflection on the Setup
The main issue with the previous setup (continuous model delivery) is fixing the pipeline deployment. Earlier pipelines had to be manually tested by the model development team and operational teams to ensure smooth functioning of every component along with their compatibility with the application. However, in this setup, testing is automated which gives flexibility to the teams to build and deploy pipelines more easily than before. As a result, we get a major advantage where businesses can now keep up with the significant changes in the data w.r.t data requiring the creation of new models as well as new pipelines and can also capitalize on the state-of-the-art MLl architectures. All thank to creation of rapid pipelines and deployment combined with continuous model delivery from the previous setup.
Ksolves has handled deployments on different platforms as per the needs of the business. We have implemented the above described pipelines in three blogs. . . . . . . . . . .
To refer earlier blogs, visit the link given below:
- What is MLOps – Make your ML Model Production Ready
- Link_1:
- MLOps: Continuous Model Delivery
- Link_2:
Ksolves expertise in Machine Learning
At Ksolves, we offer comprehensive Machine Learning Consulting Services that encompass the entire Machine Learning lifecycle. Our team of experts can help you design, build, and deploy robust CI/CD pipelines for your Machine Learning models, using best technologies and best practices.
Whether you are a startup or an established enterprise, Ksolves can provide you with customized solutions that fit your specific needs and requirements. With our Machine Learning Consulting Services, you can streamline your development process, improve model accuracy and reliability, and gain a competitive edge in the market.
Contact us today to learn more about how we can help you achieve your Machine Learning goals.
![]()
Frequently Asked Questions

Machine Learning is no longer a technology of the future. It is a core production capability powering fraud detection, demand […]

In recent years, machine learning (ML) has evolved from a niche technology into a vital tool across various industries. From […]

In today’s AI-powered world, data is not just fuel for machine learning, but it’s the foundation upon which intelligent systems […]












Author
About the Author Editorial Team The Ksolves Editorial Team includes certified Salesforce experts, Big Data engineers, AI/ML specialists, Zoho consultants, and experienced technology writers focused on delivering clear, actionable insights for modern businesses. With hands-on experience across Salesforce, Big Data platforms, AI/ML solutions, application development, software testing, and Zoho ERP/CRM, the team publishes practical guides, real-world use cases, and industry updates that support smarter decisions and faster growth. Every article is created to solve business challenges, guide technology adoption, and keep organizations aligned with evolving digital ecosystems.
Share with