

Solving Data Lake Challenges with Databricks Delta Lake
Big Data
5 MIN READ
May 18, 2023
![]()

Are you drowning in a sea of unstructured data? Is your Data Lake becoming more of a data swamp? Don’t worry, many businesses face challenges when it comes to managing their Data Lakes. The good news is that there is a solution that can help you overcome these challenges and make your Data Lake reliable, performant, and efficient. Databricks Delta Lake is the superhero of Data Lake storage systems that will save you from the Data Lake troubles.
In this blog, we’ll explore how Delta Lake can help you solve the challenges of managing your Data Lake.
What is Data Lake?
A Data Lake is a large repository of raw, unstructured, or semi-structured data which means data can be kept in a more flexible format for future use. Unlike hierarchical data warehouses, which organize data into files and folders, Data Lakes store data using object storage and metadata tags, making it easier to locate and retrieve data across regions.
With Data Lakes, companies can store all their data in a single location without imposing a schema, which is a formal structure for how the data is organized. Data Lakes can store all types of data, including unstructured and semi-structured data such as images, videos, audio files, and documents, which is essential for machine learning and advanced analytics. Check out our previous blog to know more about Data Lake and its benefits.
What is Delta Lake?
A Delta Lake is an open-source storage layer designed to run on top of an existing Data Lake and improve its reliability, security, and performance. Developed by Databricks, Delta Lake offers several features, including ACID compliance, data versioning, schema enforcement, partitioning, and compaction, that enable businesses to store, manage, and process their data more efficiently and reliably. It integrates with popular big data tools, such as Apache Spark, allowing users to access and process data using their existing tools and workflows.
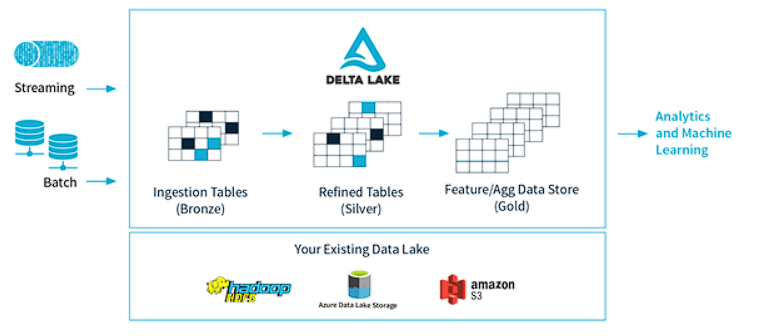
Features and Benefits of Delta Lake
Delta Lake offers several features and benefits that enable businesses to manage their Data Lakes more efficiently and reliably. Some of the key features and benefits of Delta Lake include:
- ACID Compliance: Delta Lake provides ACID (atomicity, consistency, isolation, and durability) compliance, which ensures that transactions are processed reliably and that data is accurate, consistent, and trustworthy.
- Schema Evolution/Enforcement: Delta Lake ensures that data is structured correctly, only authorized users can access or modify it, which helps maintain data governance and prevent bad data from corrupting critical processes.
- Scalable Metadata: Delta Lake’s scalable metadata feature allows it to handle petabyte-scale tables with billions of partitions and files, providing users with a high-performance solution for managing big data at scale. This makes it easy for businesses to store, manage, and process their data without worrying about scalability limitations.
- Time Travel: Delta Lake’s time travel feature enables users to access or revert to earlier versions of data, making it easy to perform audits, rollbacks, or reproduce data sets. With this feature, businesses can easily track changes to their data over time and maintain data consistency and accuracy.
- Audit History: Delta Lake’s audit history feature logs all change details, providing a complete audit trail of data changes. This feature helps maintain data governance, making it easy for businesses to track changes, monitor data access, and ensure compliance with data regulations.
Data Lake Challenges Vs. Delta Lake Solution
Challenge #1: Data Reliability
One of the biggest traditional Data Lake challenges is Data Reliability. Often, the need to continuously reprocess missing or corrupted data can become a major issue, requiring data engineers to spend significant time and energy fixing broken pipelines. This issue can arise due to hardware or software failures during data writing, leading to partial or incomplete data writes.
Solution: Delta Lake offers a solution to this challenge by providing transactional Data Lakes, where every operation is atomic, meaning it will either succeed entirely or fail entirely. This approach ensures data consistency and cleanliness, eliminating the need for tedious reprocessing of partially written data. This way, data scientists and analysts can focus on extracting valuable insights from the data and building machine learning models, without worrying about the reliability of the data.
Challenge #2: Data Lake Scalability
Data Lake scalability can also be a challenge. As the volume of data increases, it can become more challenging to store and process it efficiently. Without proper scalability measures, data processing times can increase, and costs can spiral out of control.
Solution: Databricks Delta Lake addresses the scalability issue through partitioning and compaction. By partitioning data, Delta Lake can efficiently store and process large volumes of data. Compaction enables Delta Lake to optimize storage by consolidating small files into larger ones, reducing the overall storage footprint. These features enable Delta Lake to scale efficiently and cost-effectively, making it an ideal solution for businesses dealing with large amounts of data.
Challenge #3: Quality Enforcement
Data Validation and Quality Enforcement is a critical challenge in data applications because poor data quality can result in unreliable data and poor business decisions. Unlike software applications, data quality problems can often go undetected and lead to data pipeline failures.
Solution: Delta Lake addresses this challenge by providing powerful data quality enforcement tools like schema enforcement and schema evolution. These tools, coupled with Delta Lake’s ACID transactions, enable data scientists and analysts to have complete confidence in their data, even as it evolves and changes over time. By ensuring the quality of the data, Delta Lake makes it possible for businesses to make accurate, data-driven decisions that drive better business outcomes.
Challenge #4: Data Governance
Another challenge of managing a Data Lake is data governance. As Data Lakes are often used by multiple teams across an organization, it can be challenging to ensure that data is accessed and used appropriately. It’s crucial to maintain data governance to ensure that the right people have access to the right data at the right time. This is especially important when dealing with sensitive data, such as personally identifiable information (PII) or financial data.
Solution: Databricks Delta Lake offers several features to help with data governance, including data versioning and schema enforcement. With data versioning, users can easily track changes in data, ensuring that data is not overwritten or lost. Schema enforcement ensures that data is structured correctly, and only authorized users can access or modify it. By providing these features, Delta Lake enables organizations to maintain data governance while still allowing users to access the data they need.
Challenge #5: Integrating Batch and Streaming Data
As data continues to grow at an unprecedented rate, Data Lakes must combine both streaming and batch data to remain updated. Traditionally, a lambda architecture was used to address this challenge, but it required separate code bases for batch and streaming, making it difficult to build and maintain a unified and easily manageable Data Lake.
Solution: Delta Lake solves the challenge of combining batch and streaming data by providing a unified and easily manageable Data Lake that can serve as a source and sink for both. Delta Lake leverages its ACID transactions properties of consistency and isolation to ensure that every viewer sees a consistent view of the data, even when multiple users are modifying the table at once and new data is streaming into the table simultaneously. This ensures data reliability and enables data scientists and analysts to focus on extracting insights from the data rather than worrying about data quality and reliability issues.
Final Thoughts
In conclusion, managing Data Lakes can be challenging, but with the help of Delta Lake, businesses can overcome these challenges and take advantage of the many benefits of Data Lakes. Delta Lake offers several features and benefits that enable businesses to manage their Data Lakes more efficiently and reliably, such as ACID compliance, schema evolution/enforcement, scalable metadata, time travel, and audit history. By addressing the common challenges of data reliability, scalability, quality enforcement, and data governance, Delta Lake provides a reliable, performant, and efficient solution for businesses dealing with large amounts of data. Overall, Databricks Delta Lake is a powerful tool that can help businesses unlock the full potential of their Data Lakes and drive better business outcomes.
Expert Data Lake Analytics and Implementation Services from Ksolves
If you’re looking to implement a Data Lake or require data analytics services, Ksolves can be an ideal partner for your organization. With a team of experienced Big Data consultants, Ksolves offers end-to-end services to help you successfully design, implement, and maintain your Data Lake. Our proven expertise in building Data Lakes can help you ensure the security, scalability, and performance of your Data Lake implementation.
As an established Big Data Consulting Company, Ksolves provides a variety of data analytics services to assist you in extracting valuable insights from your data and making informed business decisions. Overall, partnering with Ksolves can provide you with a complete solution for your Big Data needs, guaranteeing a successful Data Lake implementation and allowing you to maximize the value of your data.
![]()
Frequently Asked Questions
Does Delta Lake integrate with popular big data tools?
Yes, Delta Lake integrates with popular big data tools, such as Apache Spark, allowing users to access and process data using their existing tools and workflows.
How does Delta Lake ensure data reliability?
Delta Lake provides transactional Data Lakes, where every operation is atomic, ensuring data consistency and cleanliness and eliminating the need for tedious reprocessing of partially written data.
What is Delta Lake’s time travel feature?
Delta Lake’s time travel feature enables users to access or revert to earlier versions of data, making it easy to perform audits, rollbacks, or reproduce data sets.















AUTHOR
Big Data
Anil Kushwaha, Technology Head at Ksolves, is an expert in Big Data. With over 11 years at Ksolves, he has been pivotal in driving innovative, high-volume data solutions with technologies like Nifi, Cassandra, Spark, Hadoop, etc. Passionate about advancing tech, he ensures smooth data warehousing for client success through tailored, cutting-edge strategies.
Share with