Project Name
How Ksolves Leverages AWS Glue: A Serverless Solution for Transforming Data Matching

![]()
One of our clients, a Technology and software product-based company, faced challenges in data matching, entity resolution, and analyzing datasets from multiple sources. One challenge was identifying the standard identifiers, making data matching non-trivial.
The key challenges include:
- The client grappled with several critical challenges in their data-matching project.
- The foremost concern was data quality management, with inconsistent, inaccurate, and missing data compromising the project's integrity.
- Duplicates and varying data formats further complicate matters. Scalability was another key issue, given the need to adapt to fluctuating data loads and surges in demand while ensuring efficient resource allocation.
- The deployment on AWS involved intricate tasks like defining Serverless ETL workflows, setting up data pipelines, managing task dependencies, and monitoring.
- These challenges had to be overcome to ensure the project's success and the generation of reliable insights.
To address these challenges:
- We harnessed the power of AWS Glue, a serverless ETL service. AWS Glue facilitated the seamless execution of multiple Spark jobs, efficiently processing and transforming the data. It also played a pivotal role in data cleansing, ensuring that data quality issues were effectively resolved.
- Incorporating AWS EventBridge into the solution allowed us to monitor job statuses in real-time and trigger automatic responses to job events.
- This enhanced the reliability and efficiency of the project, ensuring that potential issues were addressed promptly.
- AWS Lambda played a crucial role in orchestrating the workflow. It was utilized to trigger AWS Glue jobs and seamlessly integrated with a REST API to provide a user-friendly interface for job initiation.
- We leveraged AWS S3 integration for data storage, which offers a scalable and cost-effective solution for reading and writing data. Additionally, a database was used to store metadata and job details, facilitating easy access to critical information.
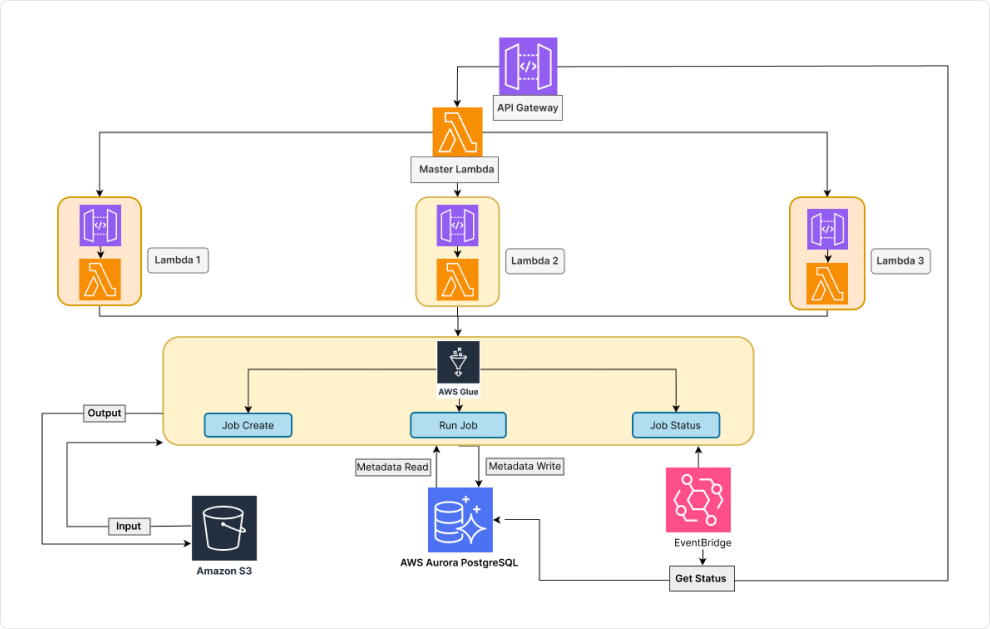
In conclusion, our comprehensive solution, leveraging AWS Glue for Spark ETL jobs, AWS Lambda for workflow orchestration, EventBridge for real-time monitoring, and S3 for data storage, effectively addressed the client’s challenges. By adopting this advanced technology stack, we provided a robust, scalable, and automated solution for data-matching algorithms and entity resolution. Our approach not only tackled data quality management issues but also ensured that the client’s project could seamlessly scale to accommodate fluctuating data demands, empowering them with a high-performance, future-proof solution.
Streamline Your Business Operations with Our AWS Glue Spark Solutions!













