

MLOps: Continuous Model Delivery
Machine Learning
5 MIN READ
February 21, 2023
![]()

It has been clearly observed that manual implementation as the first MLOps setup is quite flawed in how much work is needed not only to develop and deploy the ML model in the first place, but also to continuously maintain it and keep it up to par.
This setup consists of pipelines for automatic training of the deployed model along with speeding up the experimental process depicting below in the diagram below:
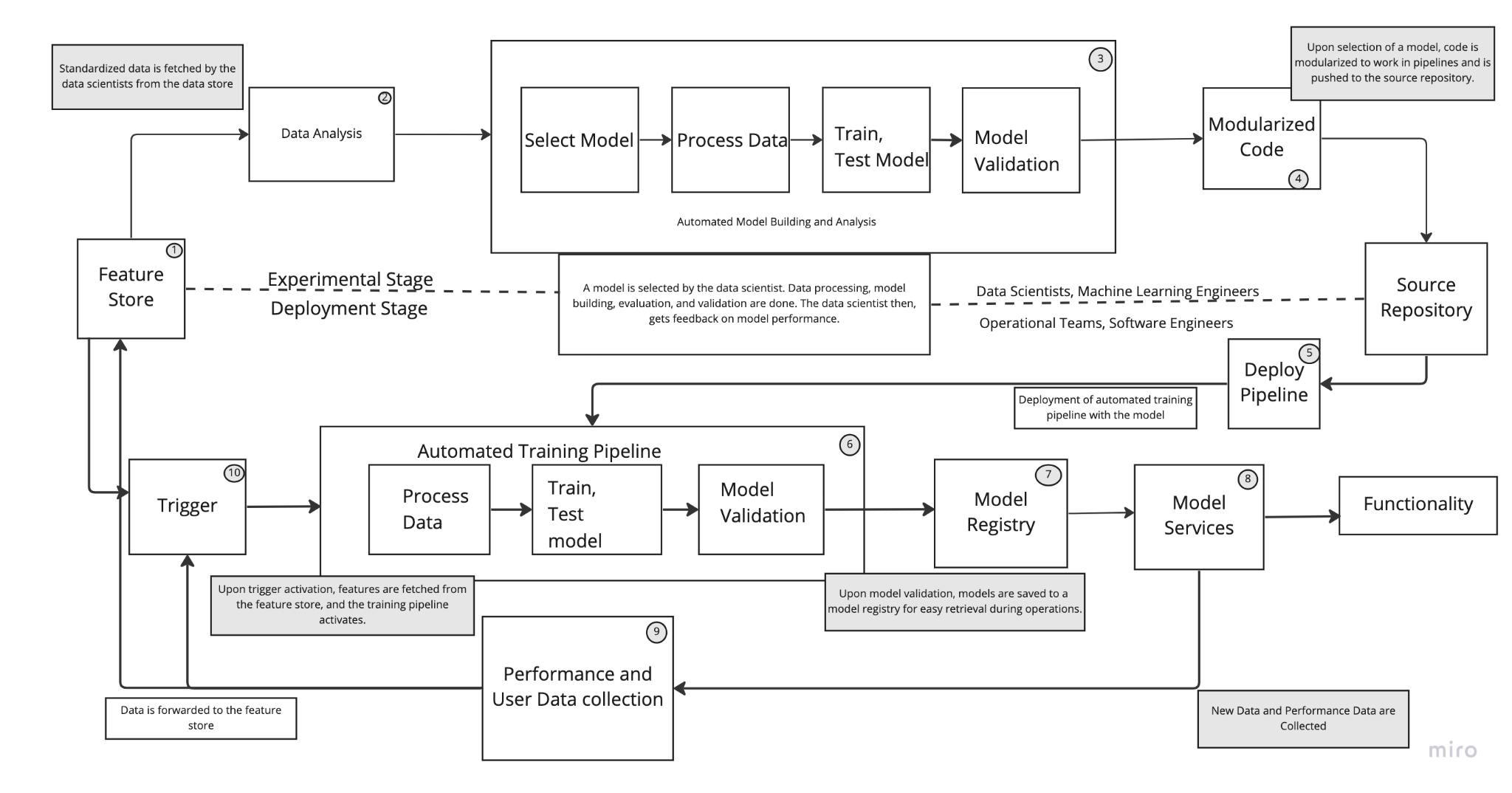
Figure: depicts a possible deployment setup of ML model with automation via pipelines
Lets understand each of the main building blocks as per the numbers depicted on the diagram.
- Feature Store: It can be considered as a data storage bin that takes the place of the data store described in the previous setup (manual integration). One reason for this is that all data in this instance can now be standardized to a common definition that can be used by all processes. For instance – all processing steps in the experimental stage will be used to exact the same data input as used by the deployed training pipeline because all data is held to the same definition. What is meant by the same definition is that the raw data is pre-processed in a procedural way and is implemented on all relevant raw data. These pre-processed data/features are kept in the feature store for the pipelines to draw from, it is also ensured that every pipeline uses features pro-processed as per this standard. As a result, any perceived differences in trends among different pipelines won’t deviate frompro-processing procedures.
- Data Analysis: Data is analyzed further in this step to give ML engineers an idea how the final data look like before model training and so on, just like in the manual setup. Additionally, this step also gives an idea of whether there is a need to build a new model or update the current model.
- Automated model building and analysis: In this stage, data scientists and ML engineers can select a model, select and tweak its hyper-parameters, and allow the pipeline to automate the entire process. Pipeline will automatically process the data, build and train the model, evaluate and validate it. During validation, the pipeline may automatically tune the hyperparameters and optimize performance. It might be possible that some manual intervention is required (debugging, for instance, when the model is particularly large and complex or the model might have a novel architecture) otherwise automation will take care of generating an optimal model. In this way, the development process in the experimental stage is sped up massively. Thus ML engineers can perform frequent experiments which can boost overall efficiency as well as increase productivity and optimal solutions can be found quickly.
- Modularized code: The experimental stage is set up to make the pipeline and its components modularized. In this, ML engineers define and develop some models, and the data is standardized to specific definitions. It means, there is no code that will only work on specific models and specific data but it can be done with generalized cases of models and data. This is called modularization, where the whole system is divided into individual components and each component is assigned a specific function and these components are switched out depending upon variable inputs. Additionally, this kind of structure also lets you swap the model if required, so there is no need to develop the entire new pipeline for every new model architecture.
- Deploy pipeline: In this step, the pipeline is deployed manually and is retrieved from source code. Due to modularization, the pipeline is operated independently and automatically trains the deployed model on any new data if needed, and the application which is built around the structure of the code that has all components will work independently. Development team has to build different parts of the application around the pipeline and accordingly their modularized components – first time around. After that the pipeline works smoothly and seamlessly with the applications as long as the structure remains constant. However, it is important to mention that the structure of the pipeline can be changed depending on the model. The main takeaway is that the existing pipelines should be able to handle many more models before having to be restructured compared to the setup before where “swapping” models meant you only loaded updated weights.
- Automated Training Pipeline: This pipeline contains the model that provides its services and is set up in such a way that can automatically fetch new features upon activation of the trigger. When a pipeline finishes updating a trained model, that model is sent and saved to the model registry, a storage that contains all trained models for ease of access.
- Model Registry: This is a storage unit that holds model classes/weights. Its purpose is to hold trained models for easy retrieval by any application (also a good component to add to an automation setup). Without model registry, all model classes/weights would just be saved to whatever source repository was established – but this way, we provide a centralized area of storage for these models. This serves to bridge the gap between ML engineers, software developers and operational teams since it is easily accessible by everyone – this is an ultimate goal of the automation setup.
This registry along with an automated training pipeline assures continuous model delivery services as models can be updated frequently, pushed to the registry and deployed without going through the entire experimental process/stage.
- Model services: Here our application pulls the latest, best performing model as per the requirements from the model registry and makes use of its prediction services.
- Performance and user data collection: At this stage, new data (raw data) is collected as usual along with metric performance related to the model. This data is sent to the feature store , where the new data is pre-processed and standardized to make it available for the development and deployment stage and there should be no discrepancies between the data used by either stage. Based on that data – decisions like whether or not to build a new model along with new architecture can be made.
- Training pipeline trigger: This trigger, upon activation, initiates the automated training pipeline for the model which is deployed and allows for retrieval of features from the feature store. Trigger can have any of the following conditions:
- Manual trigger: Perhaps the model is to be trained only when the process is manually initiated. For example, data scientists/ML engineers can choose to start this process after reviewing the model performance and data concluding that the deployed model needs to be trained on fresh batches of data.
- Scheduled training: Perhaps the model is set to train on a specific schedule – could be a certain time on the weekend, everynight during the lowest traffic hours, every month and so on.
- Performance issues: Performance data indicates that the model’s performance has dipped below a certain benchmark. This can automatically trigger the training process to get the performance back as desired up to par.
- Changes in data patterns: Instead of waiting for the performance hit to activate the trigger, the model itself begins training on new data immediately. It is based upon the sufficient detection of changes in the data (anomalies/unidentified trends), allowing the company to minimize any potential losses from such a scenario.
Reflection on the Setup
This sort of setup resolves many issues from the previous setup. Thanks to pipeline integration in the experimental stage. Building a pipeline automates the process of whole model training, validation and testing. The ML engineers (model development team) now only build models and can reuse any of the training, validation, and testing procedures that are still applicable to the model. At the end of the model development pipeline, relevant model/business metrics are collected and displayed to the application user. These business metrics can help the model development team to quickly prototype and arrive at optimal solutions even faster than they would have without automation. Now, it is possible to run multiple pipelines on different development models and compare all of them at once. Additionally, thanks to the modularised code, through which pipeline can simply swap out model classes along with their weights when deployed. Furthermore, the developed pipelines also make it easier for software development and operational teams to deploy the models and their respective pipelines. As everything is modularised, teams don’t need to work on integrating new model classes into the application every time.
While this setup provides flexibility and solves most of the issues that plagued the original setup, there are still some challenges that need to be addressed. Firstly – there are no mechanisms in place for debugging and testing the developed pipelines, it is manually done before they are pushed to the source repository. Secondly, when the pipelines are manually deployed, there is a chance when the structure of the code is changed, the engineering teams rebuild the parts of the application in order to work with the new pipelines and their modularised code.
Hopefully, automation has solved many issues of building and creating new models, but the problem of building and creating new pipelines still remains unsolved. How to tackle these challenges – take a look at the last of the three setups – “Continuous Integration/Continuous Delivery of Pipelines” in the next blog.
![]()

Machine Learning is no longer a technology of the future. It is a core production capability powering fraud detection, demand […]

In recent years, machine learning (ML) has evolved from a niche technology into a vital tool across various industries. From […]

In today’s AI-powered world, data is not just fuel for machine learning, but it’s the foundation upon which intelligent systems […]












Author
About the Author Editorial Team The Ksolves Editorial Team includes certified Salesforce experts, Big Data engineers, AI/ML specialists, Zoho consultants, and experienced technology writers focused on delivering clear, actionable insights for modern businesses. With hands-on experience across Salesforce, Big Data platforms, AI/ML solutions, application development, software testing, and Zoho ERP/CRM, the team publishes practical guides, real-world use cases, and industry updates that support smarter decisions and faster growth. Every article is created to solve business challenges, guide technology adoption, and keep organizations aligned with evolving digital ecosystems.
Share with