

Uncover the Inner Workings of Apache Cassandra: An Architectural Exploration
Apache Cassandra
5 MIN READ
June 7, 2024
![]()

Apache Cassandra is a distributed NoSQL database management system renowned for its scalability and fault tolerance, making it invaluable for businesses grappling with massive volumes of data. The Apache Cassandra architecture embodies decentralization, guaranteeing exceptional availability and performance across geographically diverse data centers. This capability empowers businesses to seamlessly handle diverse workloads, from real-time analytics to mission-critical transaction processing, fostering agility and resilience in an increasingly data-driven world.
In 2024, more than 5501 companies have adopted Apache Cassandra as their preferred NoSQL database solution. This completely explains how well Apache Cassandra Architecture works best for businesses looking to manage their data.
In this blog, we will delve into the realm of Apache Kafka and Apache Cassandra performance.
An Overview of Apache Cassandra Architecture
Apache Cassandra architecture is designed for high availability and fault tolerance. It employs a decentralized peer-to-peer distribution model, where each node in the cluster is identical and independent. Data is distributed across nodes using a partitioning scheme, ensuring there is no single point of failure.
Additionally, Cassandra’s masterless architecture eliminates bottlenecks and facilitates linear scalability, allowing businesses to effortlessly handle massive amounts of data while maintaining consistent performance and resilience. Hence, Cassandra architecture is explained!
Apache Cassandra Key Features
Decentralized Structure: Cassandra operates without a master-slave hierarchy, ensuring each node plays an equal role in the system.
Ring Architecture: Its nodes are organized in a ring-like structure, facilitating efficient data distribution and fault tolerance.
Automatic Data Distribution: Data is automatically spread across all nodes, optimizing resource utilization and enhancing system resilience.
Redundancy through Replication: Similar to HDFS, data replication across nodes ensures redundancy and data availability in case of node failures.
Memory-Centric Storage: Data is primarily stored in memory and periodically flushed to disk, prioritizing speed and responsiveness.
Hash-Based Data Distribution: Hash values derived from keys are employed to distribute data among nodes, ensuring balanced data distribution across the cluster.
These features collectively contribute to Cassandra’s robustness, scalability, and performance in distributed computing environments.
Apache Cassandra Requirements You Should Know
The Apache Cassandra architecture was meticulously crafted to meet several critical requirements, ensuring robustness and scalability for large-scale distributed systems. Let’s delve into the intricacies of Cassandra’s architecture:
Elimination of Single Point of Failure (SPOF): Unlike systems like Hadoop, Cassandra ensures no single point of failure. In a cluster of, say, 100 nodes, if one node fails, the system persists without disruption.
Massive Scalability: Cassandra facilitates the seamless addition of nodes to the cluster without any downtime, enabling clusters to scale effortlessly to accommodate hundreds or even thousands of nodes.
Highly Distributed Architecture: Both data and processing are distributed across the cluster, ensuring efficient utilization of resources and enhancing fault tolerance.
High Performance: Cassandra boasts exceptional read and write performance, enabling real-time data processing and making it suitable for latency-sensitive applications.
By adhering to these core principles, Cassandra emerges as a robust, scalable, and high-performance solution for modern distributed computing needs.
Effects of Architecture
The Apache Cassandra Architecture facilitates seamless data distribution across nodes, allowing data location within the cluster to be determined based on the data itself. With no distinction between masters and slaves, any node can process requests, retrieving data if available locally or forwarding requests to the appropriate node.
Administrators can define the desired level of data redundancy by specifying the number of replicas. For instance, critical data may warrant a replication factor of 4 or 5, while less critical data may suffice with just two replicas. Also, Cassandra offers tunable consistency and allows users to balance consistency requirements with performance considerations.
Transactions are always persisted to a commit log on disk, ensuring the durability of data. This setup sets the stage for discussing the intricacies of the Cassandra writing process in the subsequent sections of the Cassandra Architecture tutorial.
Cassandra Write Process
The Cassandra write process is designed for rapid data writes and follows these steps:
- Data is initially recorded in a commit log on disk.
- Based on the hash value, the data is routed to the appropriate node responsible for its storage.
- Nodes store the data in an in-memory table called the memtable.
- Subsequently, the data is persisted to an in-memory structure known as an SSTable (Sorted String Table), which consolidates all updates to the table.
- Finally, the data is updated in the actual table for permanent storage.
In this case, when the responsible node is unavailable, the data is directed to another node, termed a tempnode, which temporarily holds the data until the responsible node becomes accessible again.
The diagram below illustrates the writing process for the data being inserted into Table A:
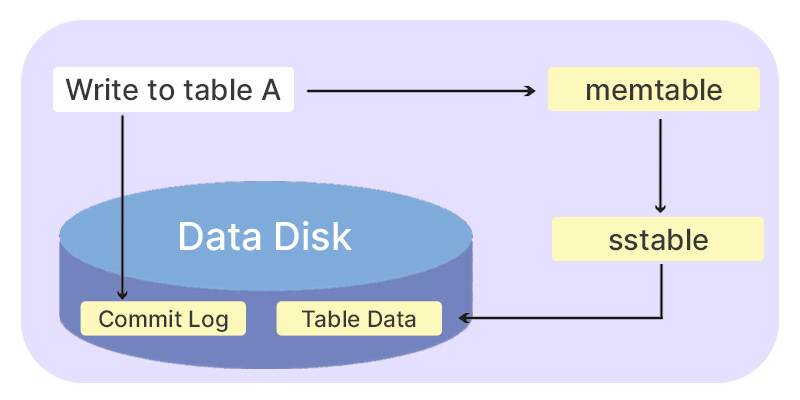
Data undergoes a dual write process for durability and performance. Initially, it’s written to a commit log on disk for persistence, and simultaneously, it’s stored in an in-memory memtable. Subsequently, the data from the memtable is transferred to an SSTable, which acts as the basis for updating the actual table.
In the upcoming section of the Cassandra architecture tutorial, we will delve into understanding the concept of a rack.
Rack
In network topology discussions, the term “rack” refers to a grouping of machines within the same physical enclosure. Each machine within the rack possesses its own CPU, memory, and hard disk. However, it’s important to note that the rack itself does not contain any CPU, memory, or hard disk components.
Feature of the Rack:
Here are the features of racks:
- Every machine housed in a rack is linked to the rack’s network switch.
- The network switch on the rack is connected to the broader cluster network.
- All machines within the rack share a common power supply.
- It’s crucial to note that a rack can encounter failure due to two primary reasons: a network switch malfunction or a power supply outage.
- In the event of a rack failure, accessibility to any machine within the rack is lost, making it appear as if all nodes within the rack are offline.
Cassandra Read Process
The Apache Cassandra requirements for the reading process are geared toward swift retrieval of data. Reads are performed simultaneously across all nodes, ensuring efficiency. In case of a node failure, data is retrieved from the replica. The priority for selecting the replica is determined based on distance. Key features of the Cassandra reading process include:
- Data stored on the same node receives the highest priority, termed as “data local”.
- Next in priority is data stored on the same rack, termed as “rack local”.
- Following that, preference is given to data stored within the same data center, termed as “data center local”.
- Data stored in a different data center receives the lowest priority.
- To expedite retrieval, data in both the mental and SSTable is initially checked, maximizing the chance of accessing data already in memory.
In this cluster, there are two data centers, Data Center 1 and Data Center 2. Data Center 1 comprises two racks, while Data Center 2 consists of three racks. The cluster is distributed among fifteen nodes, with nodes 1 to 4 located on Rack 1, nodes 5 to 7 on Rack 2, and so forth. In the following section of the Cassandra architecture tutorial, we will delve into an example illustrating the Cassandra reading process.
Top 5 Apache Cassandra best Practices
Here are five best practices for Apache Cassandra:
Data Modeling for Query Performance:
- Design your data model based on your query patterns to optimize read and write performance.
- Use denormalization and clustering keys wisely to reduce the number of queries needed to fetch data.
Proper Hardware Selection and Configuration:
- Choose hardware configurations suitable for Cassandra’s requirements, including fast disks, sufficient RAM, and multicore CPUs.
- Ensure network connectivity and latency meet the demands of your application.
Efficient Use of Replication:
- Configure replication factor and strategy carefully to ensure data redundancy and fault tolerance without sacrificing performance or storage efficiency.
- Utilize a network topology strategy to distribute replicas across data centers effectively.
Apache Cassandra monitoring and Maintenance:
- Implement monitoring tools to track cluster performance, resource utilization, and health status.
- Perform regular maintenance tasks such as compaction, repair, and nodetool operations to optimize performance and prevent data inconsistencies.
Scale Horizontally and Incrementally:
- Scale your Cassandra cluster horizontally by adding more nodes rather than vertically scaling existing nodes.
- Plan and execute scaling operations incrementally to maintain cluster stability and minimize disruption to production environments.
These are the best practices that you need to keep in mind to leverage the full potential of Apache Cassandra. This will help your Apache Cassandra performance escalate and benefit your organization with data management.
Conclusion
In conclusion, we explained the Cassandra architecture by shedding light on its robust design and principles, from decentralized nodes to efficient data distribution. Understanding these intricacies is crucial for optimal Apache Cassandra development. There are several reasons for Cassandra, including the versatility of its architecture.
Read More: Top 5 reasons to use the Apache Cassandra Database
For further guidance and implementation of Cassandra solutions, consult experts like Ksolves. Explore the possibilities with Cassandra and propel your data infrastructure to new heights with top-notch Apache Cassandra development services.
To understand it a bit better, you can go through our Apache Cassandra use cases.



At enterprise scale, storage is never just a cost line. It is a performance variable. Every byte that does not […]












AUTHOR
Apache Cassandra
Anil Kushwaha, Technology Head at Ksolves, is an expert in Big Data. With over 11 years at Ksolves, he has been pivotal in driving innovative, high-volume data solutions with technologies like Nifi, Cassandra, Spark, Hadoop, etc. Passionate about advancing tech, he ensures smooth data warehousing for client success through tailored, cutting-edge strategies.
Share with