

Spark GraphX- World’s Leading Graph Analytics Engine
Spark
5 MIN READ
June 24, 2022
![]()

Processing relational databases for intelligent services has become old. RDBMS (Relational database management system) organizes data in tables and interconnects them using common attributes. However, today’s modern era deals with large data that has complex relationships with one another. Hence, it calls for graph databases for big data processing systems.
Do you want to switch to a graph database? Are you looking for a platform to build services from activity data? Choose Spark GraphX for your business! GraphX is Apache Spark’s API (Application program interface) for graph databases and enables parallel data computation.
GraphX works as a graph processing layer on top of Spark and hence brings the power of machine learning and big data processing to graphs. Continue reading to know how Apache Spark GraphX streamlines your workforce and everything related!
What is a Graph Database?
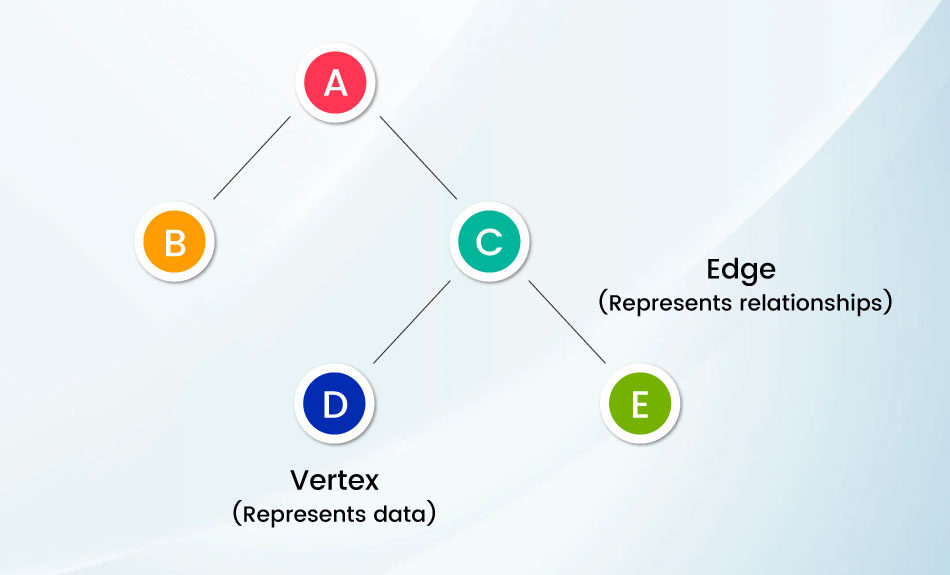
A graph database is a database that uses graph structures (with nodes and edges) to represent and store data. While the nodes represent the data items, the edge represents the relationship between these data items.
- Nodes represent any data item that you have to track. For example, it can represent entities like people, businesses, accounts etc. You can roughly compare it with a record/ relation in a relational database or a document in a document-store database.
- Edges are lines that connect the two nodes and define their relationship with one another. Edges and nodes together form a graph.
- Edges can be undirected or directed. If an edge defines the single relationship between the two nodes, it is undirected. However, if the direction of the edge determines the relationship, it is called directed.
- Properties are the knowledge associated with each node (data item). For a labelled property graph, both the data nodes and their relationships can store properties represented by key-value pairs. Moreover, edges are also directed in labelled property graphs.
Benefits of Graph Database
The graph database architecture enables data in the store to be linked directly and, in many cases, can be retrieved quickly. Querying relationships gets easy as they are perpetually stored in the database.
Understand this with an example!
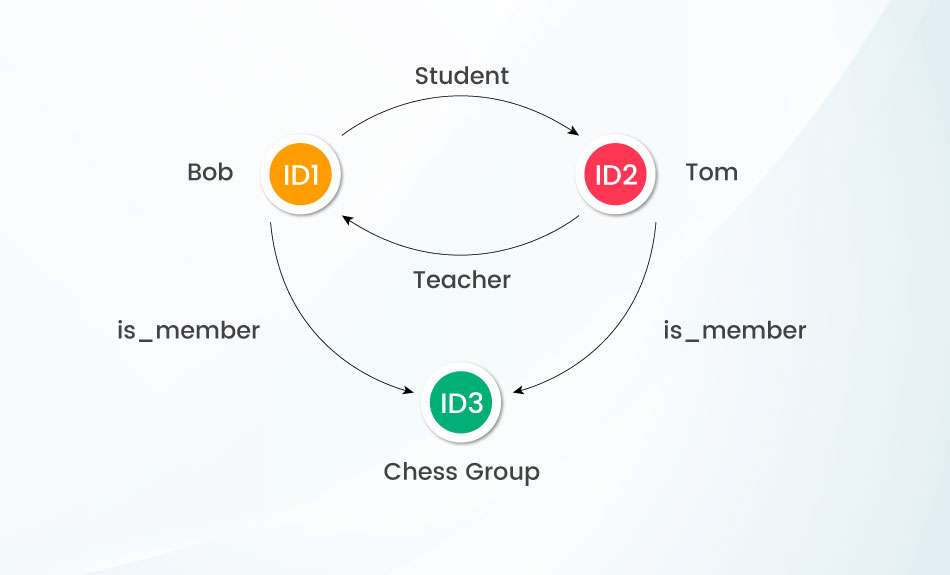
In this Graph, IDs 1, 2, and 3 are the three data items. Here ID 1 and 2 represent two persons, namely Bob and Tom, and they have a teacher and student relationship with each other. While ID 3 illustrates a group that plays chess, both ID 1 and 2 are the members of this group.
Thus examining the patterns of the graph, you can derive meaningful connections and interconnections of the nodes (data items) and their properties. Hence, with graph database structures, a constrained level of abstraction can be implemented while using a relational or document store model.
What Is GraphX?
GraphX includes a growing collection of graph algorithms and builders which help in graph data analytics. It extends Spark RDD( Resilient distributed dataset) and brings abstraction to directed multigraphs( a directed graph with multiple parallel edges sharing the same source and destination vertex).
GraphX uses a set of fundamental operators like subgraph, joinVertices, aggregateMessages and an optimized variant of the Pregel API for computation and processing.
The ability to support parallel edges simplifies modelling scenarios where multiple relationships between the same vertices exist. Each vertex is keyed with Vertex Id (a unique 64-bit long identifier), while edges have corresponding source and destination vertex identifiers.
GraphX doesn’t impose any ordering constraint on vertex identifiers. It optimizes the representation of vertex and edge types when they are primitive data types and stores them in specialized arrays. Primitive data types include int, double, etc. Hence, it reduces the memory footprint. Moreover, you can accomplish the task using inheritance property for the vertices with different property types in the same graph.
Component-wise Description of Working of GraphX
Operators Supported By GraphX
GraphX supports structural operators and joins operators. Let us discuss each one of these operators in detail.
Structural Operators
Here is a list of structural operators GraphX supports!
- Reverse Operator
It returns the graph with all the edge directions reversed and helps in computing the inverse PageRank. The operator’s benefit is that it does not modify vertex or edge properties or change the number of edges. Hence, you can implement it quickly without worrying about data movement or duplication.
- Subgraph Operator
It takes vertex and edge predicates and returns the graph with the vertices (satisfying the vertex predicate) and edges (satisfying edge predicates). The benefit of subgraph operators is restricting the graph to the vertices and edges of interest. Hence, you can easily break links in the graph.
- Mask Operator
It constructs a graph by returning a graph with vertices and edges found in the input graph. You can use it in conjugation with a subgraph operator to restrict a graph based on the properties in another related graph. The operator’s benefit is that you can run connected components using the graph with missing vertices and limit the answer to the valid subgraph.
- GroupEdge Operator
It merges duplicate edges between the pair of vertices in the multigraph. The benefit is that parallel edges (duplicate edges) can be added along with their weights in many numerical applications into a single edge. Hence, it reduces the size of the graph.
Join Operators
You may need to join data from external collections (RDD) with graphs in many scenarios. Here you need join operators. A typical example is when you want to join an existing graph with external user properties or want to pull vertex properties from one graph into another.
The joinvertices operator can join the vertices with the input RDD. Thus, you can have the output graph with the vertex properties of your choice. It is because the resultant graph will have vertex properties obtained by applying the user-defined map function to the result of the joined vertices.
Neighborhood Aggregation
Graph analysis is done by aggregating information about the neighborhood of each vertex. Understand this with an example:
If you want to know the number of followers for each user, many iterative algorithms repeatedly aggregate properties of neighboring vertices. It uses graph algorithms like PageRank, Shortest Path, and connected components to find the current PageRank Value, the shortest path to the source, and the smallest reachable vertex id properties of neighboring vertices.
To improve performance, the core aggregation operation in GraphX is graph.AggregateMessages instead of graph.mapReduceTriplets. AggregateMessages applies a user-defined sendMsg function to each edge triplet in the graph. Later, it uses the mergeMsg function to aggregate those messages at their destination vertex.
Computing Degree Information
The number of edges adjacent to each vertex determines the degree of each vertex. You need to know the in-degree, out-degree, and total degree of each vertex. A class, namely GraphOps, contains a collection of operators to compute such degrees for each vertex.
Sometimes, it is easier to compute by collecting neighboring vertices and their attributes at each vertex.
Caching and Uncaching
Like Spark that doesn’t have RDD persisted in memory by default and must be explicitly cached when using them multiple times, GraphX too needs to call Graph.cache() first to use graph multiple times. If there are multiple iterations, uncaching also becomes important for better performance.
For iterative computation, intermediate results from previous iterations are stored in the cache. Soon they are not needed; they are removed from the cache for fast performance. It involves:
- Materializes (caching and forcing) a graph or RDD every iteration
- Uncaching all other datasets
- It uses the materialized dataset in future iterations
Graphs are composed of multiple RDDs and need the Pregel API to unpersist intermediate results correctly.
Spark GraphX Pregel API
Graphs are recursive data structures where the properties of vertices depend on their neighboring vertices, which in turn depend on the properties of their neighboring vertices. Hence, a graph must have a fixed point condition to stop recursive iterations. GraphX uses a variant of the Pregel API.
The Spark Pregel operator works in a series of steps. Each vertex receives the sum of inbound messages, computes a new value for the vertex property and then sends a message to neighboring vertices in the next step. Here messages are computed in parallel as a function of edge triplets. Moreover, message computation has access to both source and destination vertex attributes. Vertices that don’t receive messages are skipped, and the Pregel operator terminates iterations and returns a graph when no messages are remaining.
Key Highlight:
Unlike standard Pregal implementations, vertices in GraphX can only send messages to neighboring vertices. Message construction is done in parallel with a user-defined messaging function, allowing additional optimization in GraphX.
Graph Builders
GraphX provides several ways of building a graph from a collection of edges and vertices in RDD or disk.
- Edges are left in their default partitions.
- Graph.apply creates a graph framework from RDDs of vertices and edges. It automatically creates any vertices mentioned by the edges and assigns them the default value.
- Graph.fromEdgeTuples creates a graph processing layer from only the RDD of edge tuples. It assigns the edges the “value 1” and automatically makes vertices as mentioned by edges ( the edges created are also set default values).
Benefits of GraphX for Your Business
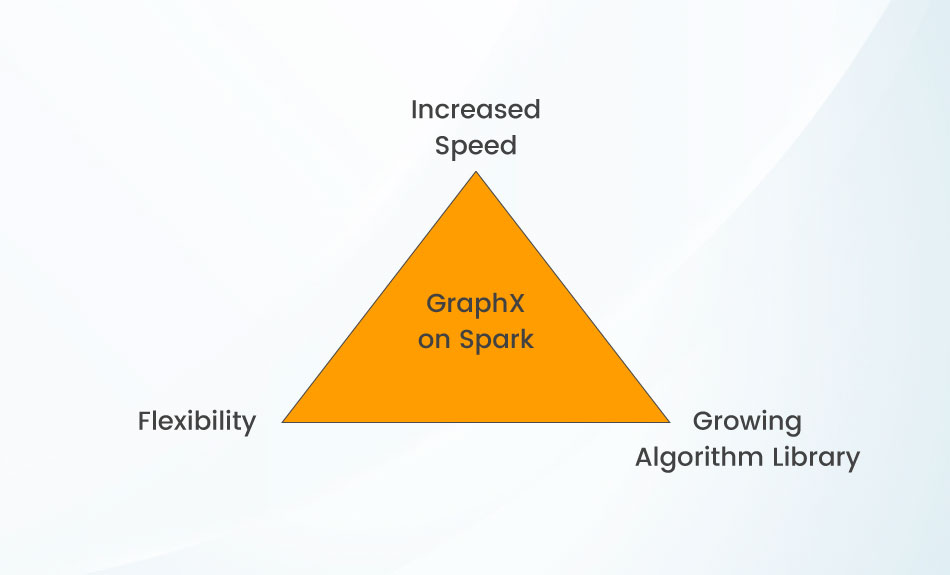
With industry-leading quality on color separations, digitized embroidery files, pixel perfect mockup product marks, GraphX is sure to call for the success of your business. Here is a list of Spark GraphX features:
Flexibility
GraphX offers flexibility and works seamlessly with both graphs and collections. Hence, you can view the same data as graphs or collections.
- It unifies ETL, exploratory analysis, and iterative graph framework computation within a single system.
- It incorporates Spark data processing pipelines with graph processing.
- Transform and join graphs with RDDs efficiently.
- Writes custom iterative graph algorithms using the Pregel API.
Speed
It is one of the fastest specialized graph processing engines while retaining Spark’s flexibility, fault tolerance, and ease of use features.
Algorithm Library
GraphX comes up with various graph algorithms and a highly flexible API. You can choose any of them from its graph-processing library as per your need. Top list includes:
- PageRank
- Connected components\
- Label propagation
- SVD++
- Strongly connected components
- Triangle count
Built-in libraries include:
- SQL and DataFrames
- Spark Streaming
- MLlib (machine learning)
- GraphX (graph)
Application Of GraphX
Apache Spark GraphX find massive application in network analysis that includes
- Telecommunication network- we can view each mobile device on the laptop as nodes and connections between them as links.
- Bioinformatics- chemical compounds act as nodes and reactions between them as links.
- Social networks- members as nodes and different activities between nodes as links.
Conclusion
GraphX is a part of the Apache Spark project and gets updated with each Spark release. You can download Spark and will find GraphX as a module. You can deploy Spark on a cluster if you want to run it in a graph database clustering node, or you can choose to run it locally on a multicore machine. You can also connect to Ksolves for technical guidance.
Ksolves is the best software development vendor to cater to all needs of your GraphX project. We have a team of experts equipped with the skills of Apache Spark development and related services.
Contact us at sales@ksolves.com, or you can call us on +91 8130704295 for complete Apache Spark Services.
Faqs
1. What is the best feature of GraphX?
The best thing about GraphX is its speed. It is one of the fastest specialized graph processing systems.
2. What is Apache Spark, and is GraphX related to it?
Apache Spark is the software framework that combines both data processing and AI applications. GraphX is a new component in Spark and works as a graph processing layer on top of it.
3. How is GraphX different from Giraph?
GraphX reads graphs from Hive, while Giraph needs extra programming effort.
![]()















AUTHOR
Spark
Atul Khanduri, a seasoned Associate Technical Head at Ksolves India Ltd., has 12+ years of expertise in Big Data, Data Engineering, and DevOps. Skilled in Java, Python, Kubernetes, and cloud platforms (AWS, Azure, GCP), he specializes in scalable data solutions and enterprise architectures.
Share with