


What is MLOps – Learn how to Make your ML Model Production Ready
Machine Learning
5 MIN READ
February 20, 2023

MLOps stands for Machine Learning Operations and is sometimes also referred to as “ModelOps”. It refers to an engineering discipline that combines ML Model Development (Dev) with ML Model Deployment (Ops). With this, engineers can streamline continuous model development along with the continuous delivery of high-accuracy models in production.
Why Machine Learning Operations (MLOps)?
Till now, we have dealt with a decent amount of data and developed a few models at a minimal scale. At present, we are creating an ecosystem of indulging automation in wide applications and this can lead to a lot of technical challenges that arrive from building and deploying ML-based applications.
MLOps assist with unique techniques for AI/ML projects in every area including project management, CI/CD pipelines, and quality assurance, to improve delivery time, minimize defects, and make data scientists more productive. MLOps refers to a methodology that is built by applying DevOps techniques to ML workloads.
Similar to DevOps, MLOps relies on a streamlined approach to ML model development cycle where intersection of process, people and technology optimizes end-to-end activities which is required to develop, build, and operate ML workloads.
MLops is focused because it involves intersection of ML engineers/data scientists and data engineering with existing DevOps approaches to streamline various ML model delivery across ML model development cycle.
MLOps Setups
Before diving deep into specific MLOps setups, let’s first establish 3 different setups with varying degrees of automation which include:
- Manual implementation
- Continuous model delivery
- Continuous integration/continuous delivery of pipelines
Manual implementation: It is a setup where no MLOps principles are applied and everything is manually implemented. All model development steps including data Analysis, feature engineering and model classification are all manually implemented. Software development teams need to manually integrate trained models into the application, and operational teams must ensure that all application functionality is preserved along with data collection and model performance metrics. The information will give you a deeper understanding about your model as well as the user base model which is servicing. The probability is high that you have to update it in order to observe and maintain its performance on new data. One needs to keep this in mind after following the process depicted in the figure below:
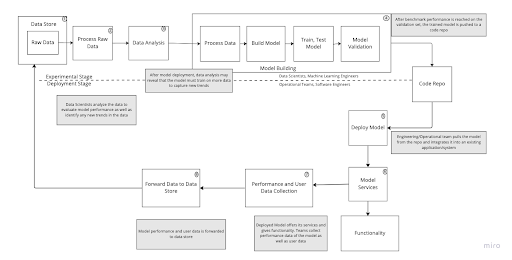
Figure depicts a deployment setup for an ML model that doesn’t follow any MLOps guidelines/principles. Dotted arrow borders indicate that progression to the next step is conditional on the current step’s condition. For example – in the validation step, ML engineers must take care that the model meets a minimum performance benchmark before pushing model class to the repo.
The above flow diagram can be split into two stages:- Experimental stage and Deployment stage. Experimental stage involves the ML side of the work flow whereas deployment stage takes care of model integration to various applications along with maintaining operations.
Experimental Stage:
- Data Store: It refers to data storage where relevant data for data analysis and model development is stored. Example: S3 bucket, Hadoop which could store large volumes of data. Data scientists can pull raw data from data stores and start conducting experiments w.r.t data analysis
- Process Raw Data: Initial data analysis on raw data is necessary to collect relevant information. This step also includes purging faults and corrupted data. It is quite natural that when company collects a large amount of data, some segments of it are bound to be corrupted in some way eventually, and it’s always advisable to remove these unwanted segments to get desirable model performance. For example, one missing value (null entry) can completely break the training pipeline for a neural network used for some regression use cases (example – value prediction) task.
- Data Analysis: This step involves analyzing data from all aspects. Its usage comes into the picture when a model is updated by data scientists – a few new trends can be seen in the data which needs to be considered at the time of model re-training. Additionally, it also depends on how many characteristics of the earlier (true) user base the original model was trained, as the user base changes over time, and so must the models. By “user base”, we depict the actual users who are using the prediction services provided by the model.
- Model Building Stage: It’s the same stage as discussed before, but comes into the picture while updating the model. At the time of model re-training, some layers might have to be adjusted. In the worst cases, the current model reaches its saturation stage and is unable to achieve the desired business metrics. In that scenario, an entirely new model has to be built. If there are no such issues – one can just further train, test and validate the model, and push it to the code repository upon meeting the desired business metrics.
Deployment Stage:
- Model Deployment: At this stage, software developers must manually integrate models into the application they are developing. Whenever ML developers complete a workable model, and push it to the code repo, the software developers team must manually integrate it again. Furthermore, software developers need to handle the testing of a model once it is integrated into an application as well as the rest of the application.
- Model Services: This is the stage, where the model is finally deployed (production ready) and interacting with its respective user base in real-time. At this stage, the operational team also steps in to maintain software functionality. For example, if there are any issues with respect to model functionality, the operational team must specify/record the bug and forward it to the model development (ML engineers) team.
- Data Collection: The operational team can also collect relevant data and performance/business metrics. This data collection is crucial for companies to make their strategic decisions. For instance, a company might want to know which services are most popular among its user base, or how accurate its ML models are performing so far.
- Data forwarded to data store: At this stage, the operational team sends data to the data store. A certain amount of automation is assumed by the operational team due to the massive amount of data. Additionally, the application itself could also be in charge of forwarding the collected data to the data store.
Reflection on the Setup
Right away, one can notice various problems that may arise from manual implementation. First – the entire experimental stage is manual – ML engineers must repeat those steps every time. Secondly, trends in the data can be changed with time. What was previously normal in the model is no longer normal for the model (example – age group with the highest number of users logging into websites is composed of people in their early twenties. A year later, teenagers can be the most dominant group). This could lead to losses in ad revenues, for instance, if that’s the service (targeted advertising) the model in this case provides. Another issue is that tools like Jupyter Notebook are popular for experimentation, prototyping and developing deep learning architectures. Even if the experiments are not performed on such notebooks, it is likely that work must be done in order to give flexibility to the code to be pushed to the source repository. For instance – constructing a model class which involves load weights, predicts, and evaluates would be ideal for a model class. Furthermore, Deep Learning is a continuously evolving field and cutting edge algorithms in the past can easily be surpassed by state-of-the-art model architectures. Thus, it’s important for the teams to continue updating their models in order to keep up with the developments in the field .
So how would we go about improving it? How can MLOps come into play? To answer these questions and surpass the limitations of the current model, refer to the second setup “Continuous Model Delivery” in the next blog.



In this setup, we are introducing a system to thoroughly test pipeline components before they are packaged and ready to […]

AUTHOR
Share with