

Apache Kafka vs Apache Spark Streaming: Understanding the Key Differences
Big Data
5 MIN READ
June 23, 2023
![]()

Real-time data processing has become an integral part of modern business operations as businesses must respond promptly to the changing data streams to maintain their competitive edge. Two of the most widely used tools for real-time data processing are Apache Kafka and Apache Spark Streaming, but their differences can make it challenging to choose the right one for your business’s specific needs.
In this blog, we’ll compare and contrast Apache Kafka and Spark Streaming, so you can make an informed decision on which tool is best suited for your organization.
Apache Kafka
Apache Kafka is a powerful tool used by many large businesses to manage and process data in real-time. It is made to swiftly and effectively handle large amounts of information from diverse sources and deliver it to different clients. The distributed commit log of Kafka, which enables real-time processing of data as it is generated, is one of its key features.
Kafka was initially developed by LinkedIn to handle an astounding 1.4 trillion messages per day. Kafka is an open-source data streaming technology that offers numerous advantages over conventional messaging systems, including high throughput, low latency, and fault-tolerance. In brief, Apache Kafka enables businesses to maintain a competitive edge in today’s dynamic business environment.
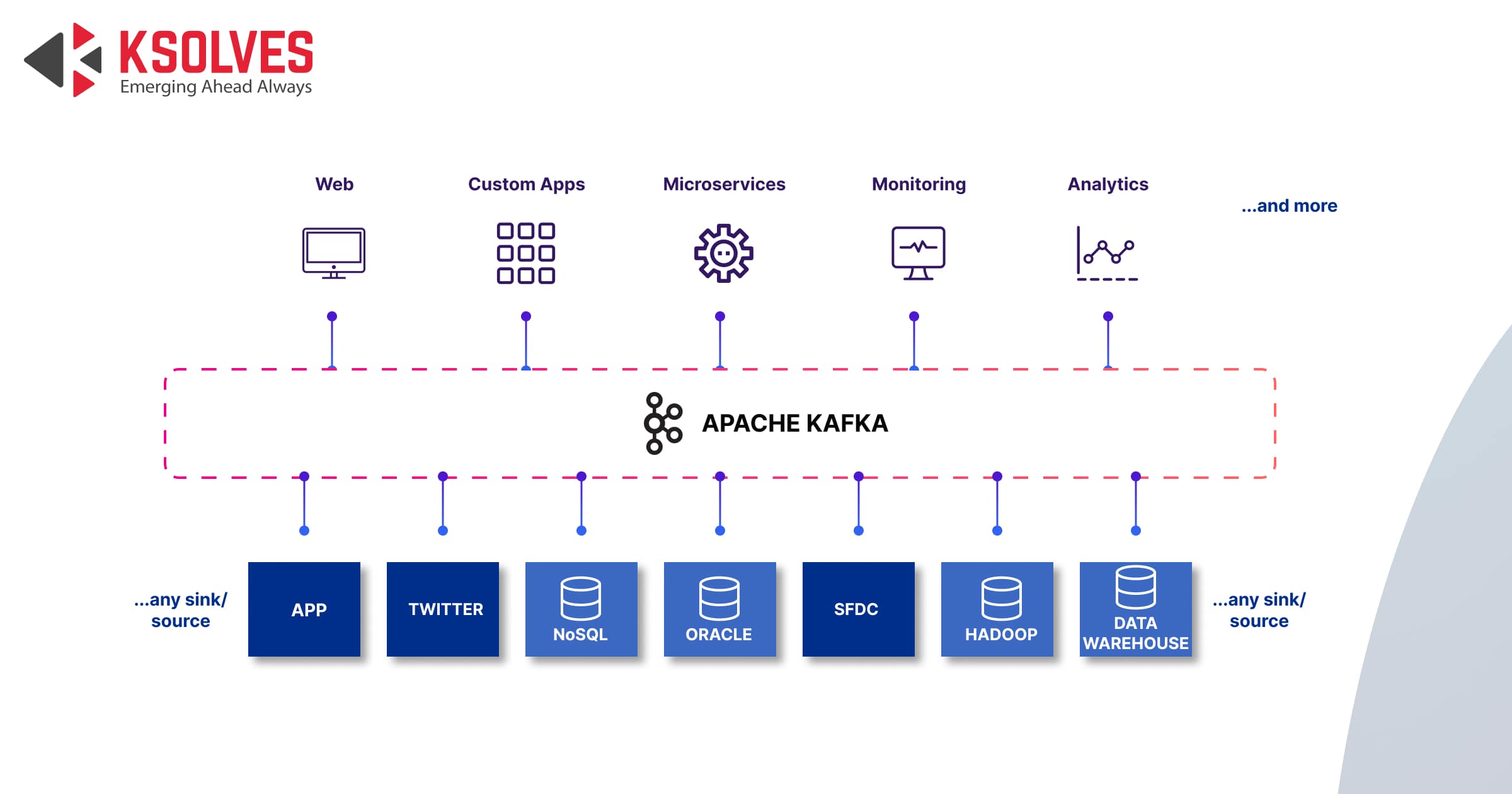
Features of Apache Kafka
- Distributed Architecture
- High Throughput
- Scalability
- Fault Tolerance
- Durability
- Stream Processing
- Low Latency
- Security
- Data Retention
Spark Streaming
Spark Streaming is a component of Apache Spark that allows for real-time data processing of data streams. Large volumes of data can be received and processed in real-time, which makes it useful for applications that demand speedy responses. Spark Streaming works by breaking up the incoming data stream into manageable batches and processing each one in parallel with Spark’s processing engine.
It can handle data from a variety of sources, such as Kafka, Flume, and HDFS, and it has the ability to filter, map, and reduce the data stream. Spark Streaming has gained popularity for creating real-time data processing pipelines and applications due to its flexibility and usability, making it a necessary tool for businesses trying to stay on top of the competition.
The following diagram explains the working of Spark Streaming.
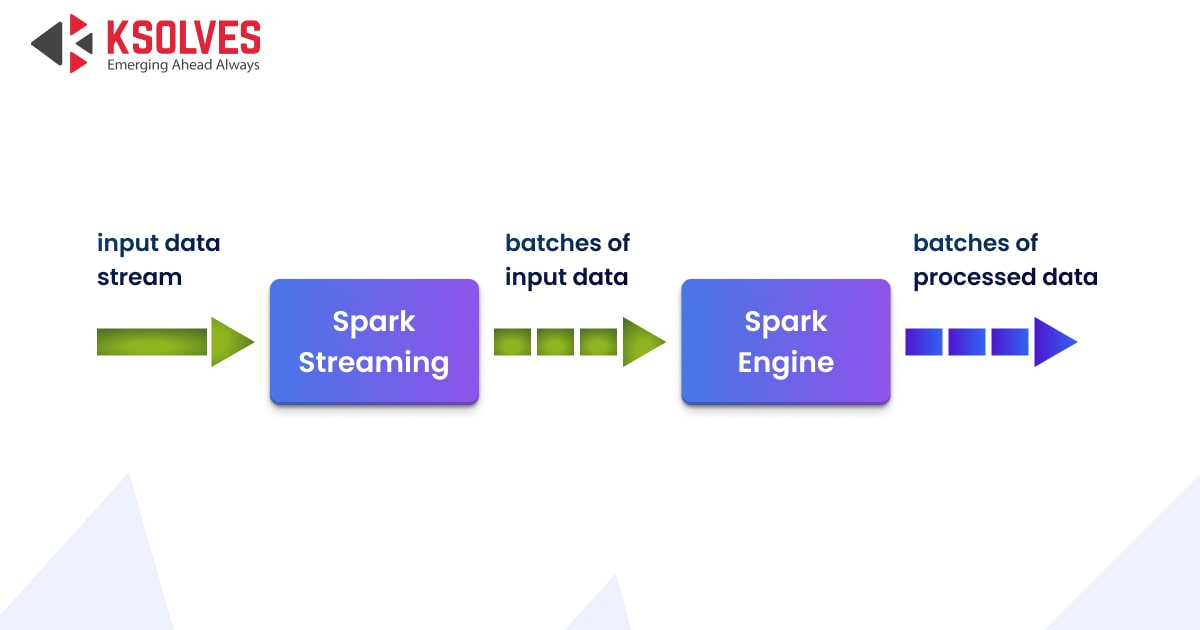
Features of Apache Spark Streaming
- Micro-batch processing
- High-level APIs
- Fault tolerance
- Easy integration
- Extensible
- Scalability
- Machine learning support
- Complex event processing
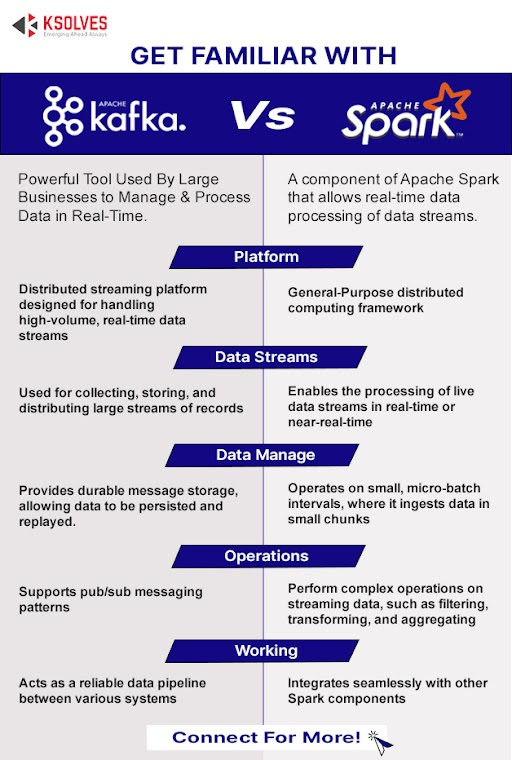
Apache Kafka vs. Spark Streaming: Key differences
| Features | Apache Kafka | Spark Streaming |
| Data Ingestion | Ideal for high-throughput, distributed data ingestion from various sources | Can ingest data from various sources, but not ideal for high-throughput data |
| Real-time Processing | Can process data in real-time and distribute to multiple consumers | Can process data streams in real-time |
| Data Analytics | Provides real-time analytics and event-driven architectures | Can perform real-time analytics, machine learning, and data warehousing |
| Fault Tolerance | Provides high fault tolerance and data replication | Provides fault tolerance, but not as high as Kafka |
| Scalability | Scales horizontally to handle large volumes of data | Scales well, but may require more resources than Kafka |
| Use Cases | Data ingestion, real-time analytics, event-driven architectures | Real-time processing, machine learning, data warehousing |
Apache Kafka vs Spark Streaming: Comprehensive Comparison
- ETL Transformation
Spark Streaming is based on Apache Spark platform, which provides a rich set of APIs for ETL (Extract, Transform, Load) transformations. Spark Streaming allows developers to write complex ETL transformations on real-time data streams using the familiar APIs of Spark. This makes it easy to perform operations like filtering, mapping, aggregating, and joining on real-time data streams.
Kafka Streams, on the other hand, provides a simple programming model for transforming data streams. It provides a DSL (Domain Specific Language) for defining processing topologies, which makes it easy to define ETL transformations. However, the DSL is not as powerful as the Spark APIs, and it may not be suitable for complex ETL transformations.
- Latency
When it comes to real-time data processing, latency is a key consideration. Data is handled in Spark Streaming in small batches at regular intervals using the micro-batch processing methodology. The latency of Spark Streaming depends on the batch interval, which can be set as low as 100 milliseconds. Spark Streaming is therefore perfect for applications that need low latency, however the latency may not be as low as that of other real-time processing solutions.
Kafka Streams, on the other hand, provides very low latency because it processes data as soon as it arrives. Data is divided among a number of nodes in a Kafka cluster in the distributed processing architecture used by Kafka Streams. Due to the extremely low latency created by this, Kafka Streams can process data in parallel.
- Processing Type
Spark Streaming and Kafka Streams differ in their processing types. Spark Streaming is a micro-batch processing engine, which means that data is processed in small batches at regular intervals. This approach provides fault tolerance and allows Spark Streaming to recover from failures easily. However, this approach may not be suitable for applications that require low latency.
On the other hand, Kafka Streams is a continuous processing engine that begins processing data as soon as it is received. Although it offers extremely low latency, this method might not be as fault-tolerant as Spark Streaming.
- Language Supported
Spark Streaming provides APIs for Java, Scala, and Python programming languages, making it easy for developers to write code in their preferred language. This allows developers to leverage their existing skills and expertise.
Kafka Streams provides a Java-based DSL for defining processing topologies. While it is possible to use other programming languages with Kafka Streams, it may require additional effort.
- Memory Management
Spark Streaming uses a batch-oriented processing model, which means that data is processed in batches. This approach allows Spark Streaming to manage memory efficiently, as it can process multiple batches in parallel. Spark Streaming also provides built-in support for memory management, allowing developers to tune memory settings for optimal performance.
Data is processed instantly upon arrival because of Kafka Streams’ continuous processing model. Since the data must be handled immediately, this method calls for a distinct memory management strategy. Developers can adjust memory settings for optimum performance with Kafka Streams’ built-in support for memory management.
Apache Kafka vs. Apache Spark Streaming Use Cases
- Apache Kafka
Uber:
Uber uses Kafka as the backbone of its event-driven architecture. Kafka allows Uber to process millions of events per second in real-time, powering features such as real-time ride tracking and analytics for driver and rider behavior.
LinkedIn:
LinkedIn uses Kafka to handle its high-volume messaging and to power its news feed. Kafka helps LinkedIn to process large amounts of data in real-time and quickly respond to user actions.
Netflix:
Netflix uses Kafka to process data from its massive user base and to power its personalization engine. Kafka enables Netflix to analyze user behavior in real-time and provide personalized recommendations to its users.
- Apache Spark Streaming
Twitter:
Twitter uses Spark Streaming to analyze tweets in real-time and to identify trending topics and monitor user sentiment. Spark Streaming allows Twitter to process large volumes of data in real-time and quickly respond to changes in user behavior.
Intel:
Intel uses Spark Streaming to monitor and analyze IoT data generated by its manufacturing facilities. Spark Streaming enables Intel to quickly detect anomalies in its manufacturing process and take corrective action.
Booking.com:
Booking.com leverages Spark Streaming to develop online machine learning features for real-time prediction of user behavior and preferences, as well as to analyze demand for hotels and enhance customer support processes.
Takeaway
In conclusion, Spark Streaming and Apache Kafka are both effective real-time data processing systems, and each has particular advantages and applications. In contrast to Spark Streaming, which is beneficial for processing data streams in real-time, ETL transformations, and machine learning assistance, Kafka is ideal for high-throughput, distributed data input from diverse sources and real-time processing.
Organizations should evaluate their specific needs and use cases before choosing between Kafka and Spark Streaming. The decision should be based on factors such as data ingestion requirements, real-time processing needs, fault tolerance, scalability, and programming language support.
Both Kafka and Spark Streaming are essential components in the real-time data processing ecosystem, and businesses can leverage their strengths to build efficient and effective data processing pipelines that can help them stay competitive in today’s data-driven world.
Ksolves: Your Partner for Apache Kafka and Spark Streaming Consulting
As a Big Data consultant with extensive experience in Apache Kafka and Spark Streaming, Ksolves can be your right partner for all your Big Data needs. At Ksolves, we have a team of certified experts who can help you with everything from designing and implementing Kafka and Spark Streaming solutions to providing ongoing support and maintenance. We offer a wide range of services, including Spark Streaming Cloud Services, that are tailored to meet the unique needs of your business.
Whether you need help with data ingestion, processing, or analytics, our team has the expertise to help you achieve your goals. As a trusted partner for many businesses, we pride ourselves on delivering high-quality services and ensuring customer satisfaction. Contact us today to learn more about how we can help you with your Apache Kafka and Apache Spark Streaming consulting needs.
![]()
Frequently Asked Questions
Can Apache Kafka and Spark Streaming be used together?
Yes, Apache Kafka and Spark Streaming can be used together to build real-time data processing applications. Kafka can be used to ingest data and serve as a messaging system, while Spark Streaming can be used to process the data in real-time. This combination allows you to handle large volumes of streaming data with low latency and high throughput.
How does Apache Kafka handle data partitioning?
Apache Kafka uses data partitioning to distribute the load across multiple nodes in a cluster. Each topic in Kafka is divided into multiple partitions, and each partition can be handled by a separate broker. This allows you to scale your application horizontally by adding more nodes to your cluster.
What are the benefits of using Spark Streaming over traditional batch processing?
One of the main benefits of using Spark Streaming over traditional batch processing is that it allows you to process data in real-time, which is useful for applications that require low-latency processing. Additionally, Spark Streaming is fault-tolerant, which means that it can recover from failures without losing data. This makes it a more reliable solution for processing large volumes of data.















AUTHOR
Big Data
Atul Khanduri, a seasoned Associate Technical Head at Ksolves India Ltd., has 12+ years of expertise in Big Data, Data Engineering, and DevOps. Skilled in Java, Python, Kubernetes, and cloud platforms (AWS, Azure, GCP), he specializes in scalable data solutions and enterprise architectures.
Share with