

A Comparison between Apache Spark vs. Apache Hadoop
Spark
5 MIN READ
July 13, 2021
![]()

When the technology world struggled with the large volume of data, frameworks that can process an enormous amount of data came into existence. Big data denotes large datasets that are structured and unstructured. Big data framework, with its holistic structure, has become the most sorted solution for enterprises for processing large data.
Two of the most popular big data frameworks are Apache Hadoop and Apache Spark. But, when both of the frameworks are equally popular and widely used, people often find them in a dilemma. Whether they should go for Hadoop or Spark? Which is better? Which framework is the best suited for their enterprise? These are some questions which we often get asked.
So, we decided to give you a better understanding of the relative differences between the two frameworks.
What is Apache Hadoop?
Hadoop came into existence as a yahoo project in the year 2006 but later became a full-fledged open-source software framework for processing large datasets. Hadoop uses a distributed file system (HDFS) and an execution engine named MapReduce to store, manage and process data across distributed clusters. Hadoop frameworks entail the following components:
- HDFS – A Hadoop Distributed File System (HDFS) manages a large set of data across a cluster and allows both structured and unstructured data.
- MapReduce – MapReduce is considered the processing component of the Hadoop framework. It assigns the data from the HDFS to the cluster and also processes the data in parallel.
- Hadoop Yarn – It is mainly used for managing resources and scheduling jobs.
- Hadoop Common – Set of common libraries to support other Hadoop Components.
What is Apache Spark?
Apache spark was first developed in UC Berkeley’s AMPLab and later taken over by the Apache Software Foundation. Just like Hadoop, Spark’s main focus is on processing data in parallel but the difference is Apache Spark works in memory. This execution of in-memory computations increases the speed of Data processing. Resilient Distributed Dataset is the data structure of spark. Apache spark has the following key components:
- Spark Core – The base engine for data processing is responsible for any fault recoveries and communication with a storage system.
- Spark SQL – Module which integrates processing with functional programming API.
- Spark Streaming – A component used for processing real-time streaming data and enables high throughput.
- GraphX – An API used for computations of graphs.
- Machine Learning Library – As the name suggests, its main task is to perform machine learning in Apache Spark.
Comparisons between Spark and Hadoop
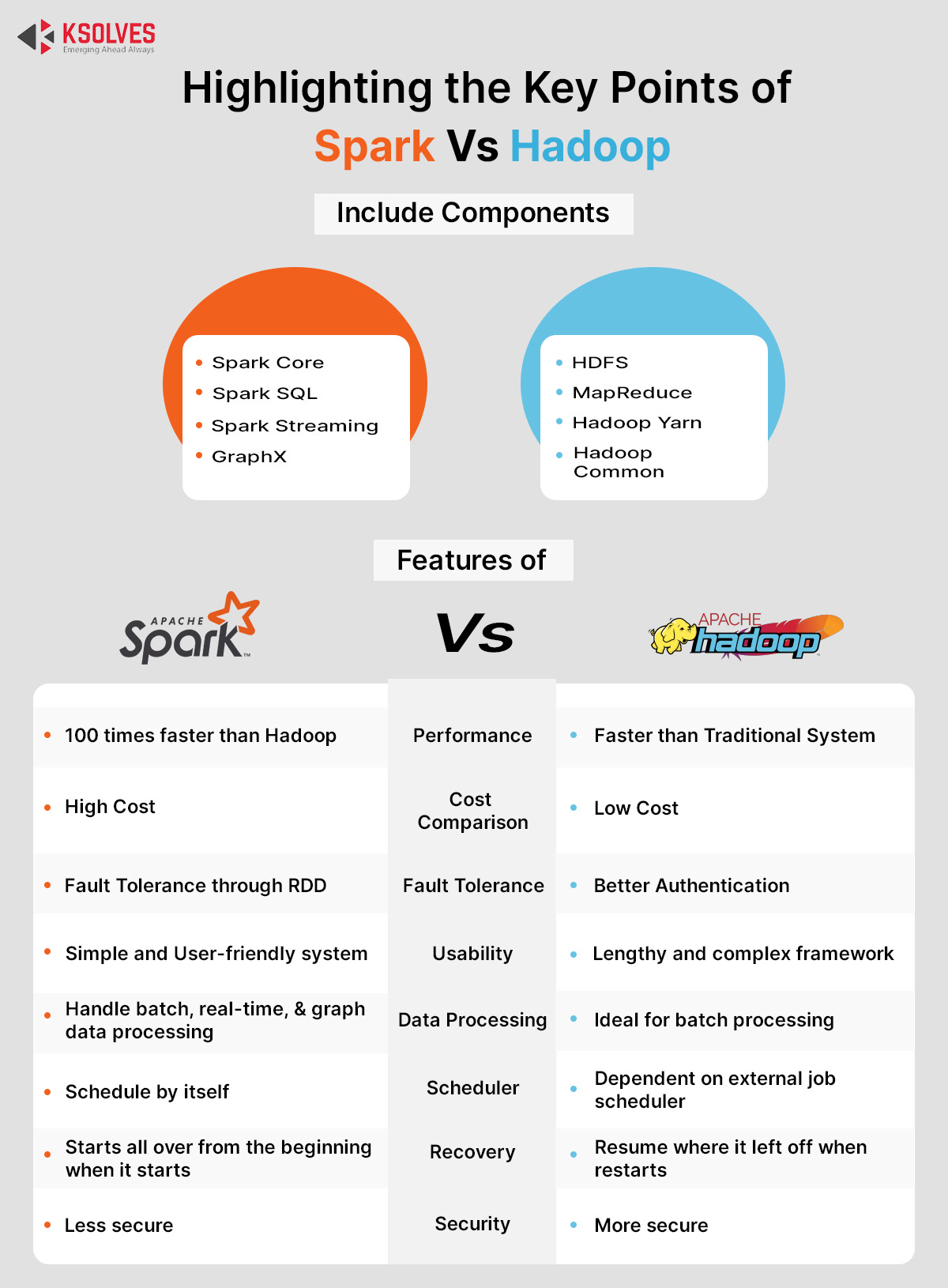
Although Hadoop and Spark are both open-source big data frameworks, they do not perform the same tasks. They are similar yet different.
Let us discuss the detailed comparison of both frameworks based on various parameters.
Performance :
If we have to draw comparisons between Hadoop and Spark, based on performance, we will see that Spark is 100x faster than Hadoop. Spark runs 100 times faster in memory and 10 times faster on disk.
The reason behind Spark being faster than Hadoop is the factor that it uses RAM for computing read and writes operations. On the other hand, Hadoop stores data in various sources and later processes it using MapReduce. But, if Apache Spark is running on YARN, it will degrade the performance and will cause RAM overhead memory leaks.
Cost Comparison
Both Hadoop and Spark are open-source, which means they are available for free and with no installation cost. However, there is a catch if you look at the overall cost of ownership of both the platforms which include infrastructure and maintenance.
If you are wondering that when these frameworks can run at a low cost, why the cost comparison should be a parameter. Well, we know that storage in Hadoop is disc-based but the Spark requires more memory in RAM. A disk is a relatively cheaper commodity as compared to RAM. Thus, Spark is more expensive than Hadoop.
Security and Fault Tolerance Comparisons
Hadoop and Spark, are both Fault tolerant but, each of them has a different approach. In Hadoop, each file is split and replicates ensuring it’s rebuilt even when a machine is down. Spark provides fault-tolerance through RDD which is the building block of Apache Spark. RDDs can refer to any dataset present in HDFS and can operate parallelly.
As far as security is concerned, Hadoop provides more authentication than Apache Spark.
Ease of Use
Spark is a simple and user-friendly system. The RDD helps the user process data using over 80 high-level operators. Spark also provides multiple APIs like Java, Scala, Python, R and, SQL.
Hadoop is a lengthy and complex framework due to its MapReduce code. Hadoop requires low-level API and lots of hand-coding.
Final Take
Hadoop and Spark are not only popular distributed systems but are helping enterprises grow across the world. They are not supposed to compete but complement each other. There are several Apache Spark use cases and several Hadoop use cases where they both are irreplaceable.
If you are eager to know more details about Hadoop development services write to us. Or, if you would like to consider Spark, write to us anyway. Ksolves is among the best Apache Spark development company and always ready to help you out with the best solution.
Email : sales@ksolves.com
Call : +91 8130704295
![]()
Frequently Asked Questions
Why Apache Spark is Faster than Apache Hadoop?
Apache Spark is faster than Apache Hadoop because it performs most computations in memory, uses a DAG execution engine for optimization, allows for data caching and reuse, offers built-in libraries for efficient processing, and provides a more streamlined API for faster development.
How Apache Spark is better than Apache Hadoop?
Apache Spark is better than Apache Hadoop because it offers faster processing with in-memory computations, optimized execution with a DAG engine, support for iterative and interactive processing through data caching, a rich set of built-in libraries, and a more user-friendly API for easier development.
How do Spark and Hadoop handle data processing differently?
Spark performs in-memory processing, which means it keeps data in memory as much as possible, resulting in faster computations. It utilizes a directed acyclic graph (DAG) execution engine and supports iterative and interactive processing through data caching.
On the other side, Hadoop, specifically its MapReduce framework, writes intermediate results to disk, resulting in slower processing. It processes data in a batch-oriented manner, dividing tasks into maps and reducing phases. Hadoop is well-suited for processing large-scale data sets efficiently.















AUTHOR
Spark
Atul Khanduri, a seasoned Associate Technical Head at Ksolves India Ltd., has 12+ years of expertise in Big Data, Data Engineering, and DevOps. Skilled in Java, Python, Kubernetes, and cloud platforms (AWS, Azure, GCP), he specializes in scalable data solutions and enterprise architectures.
Share with