The ability to act on real-time data is no longer just a competitive advantage; it’s becoming a necessity. From personalized […]
Data volumes are growing faster than most organizations can manage. Traditional tools struggle to keep up, and the gap between […]
Apache Kafka has become the backbone of modern event-driven architectures. It captures every transaction, click, sensor reading, and state change […]
No two environments are alike. Within the same organisation, two projects running on the same infrastructure can have entirely different […]
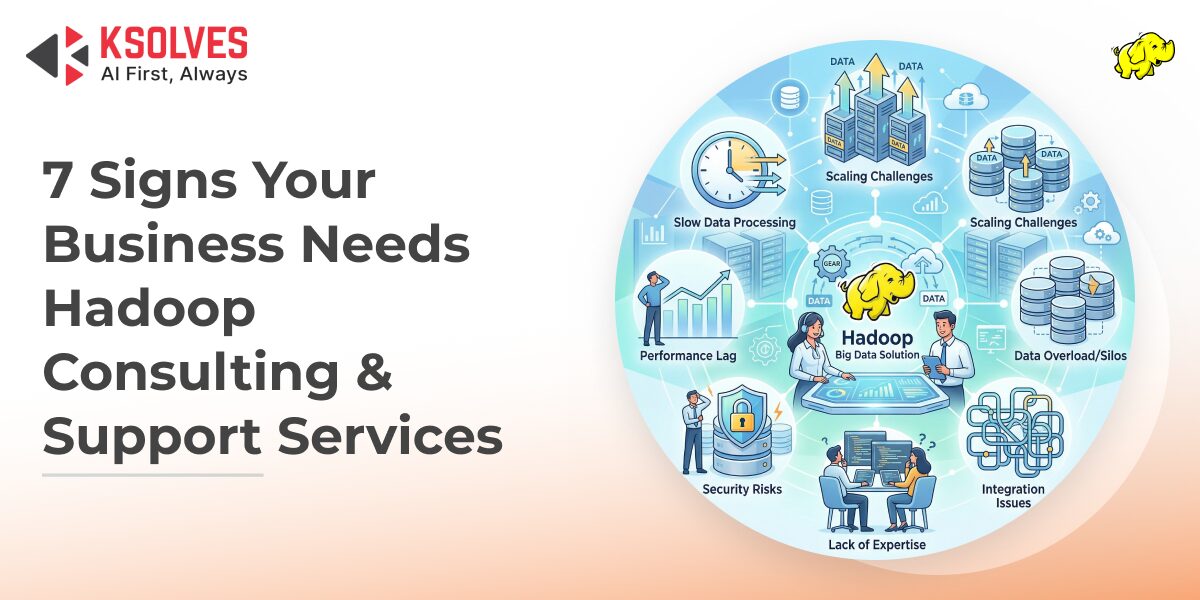
In many organizations, Hadoop was set up with high expectations. The promise was simple: Handle more data, get more insights, […]
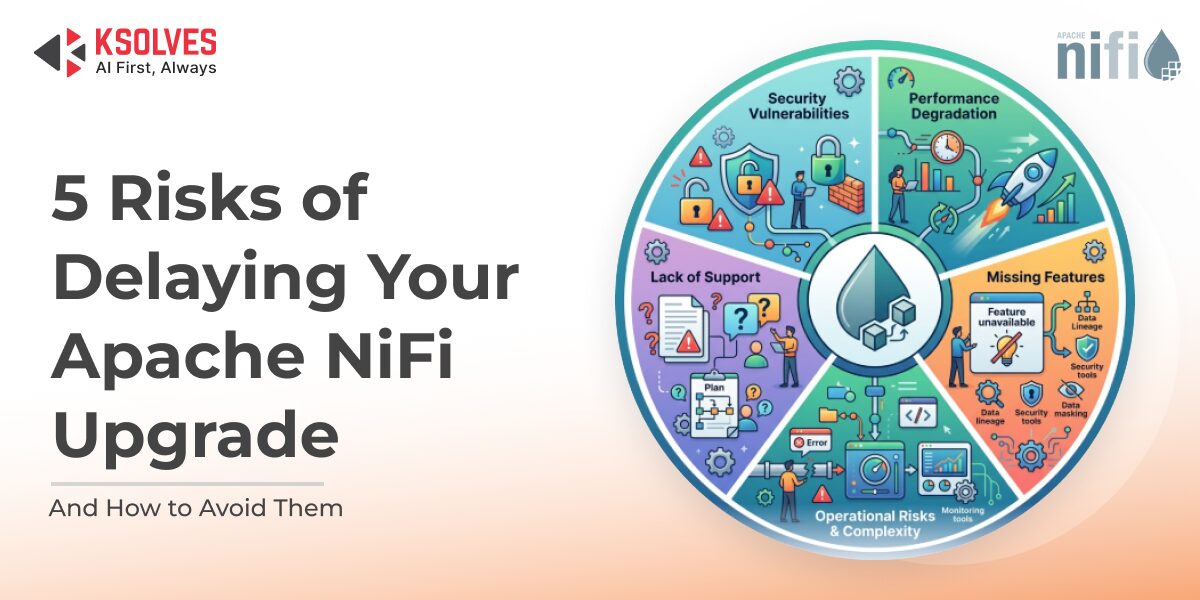
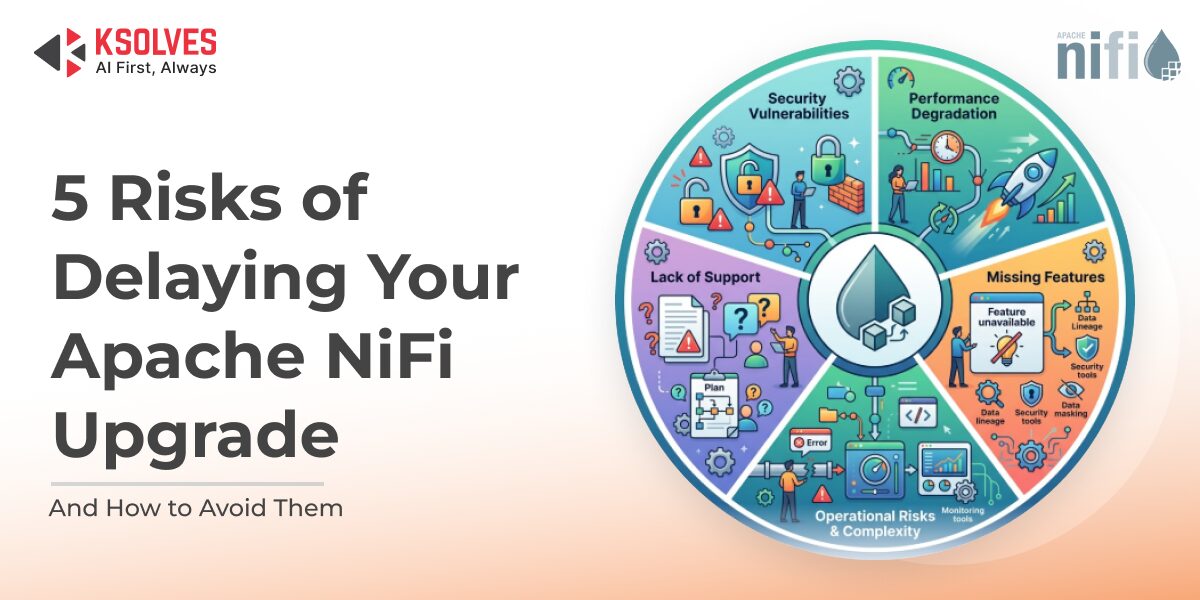
In modern data ecosystems, Apache NiFi often sits at the heart of real-time data movement, connecting diverse systems and handling […]
Redis is the backbone of real-time applications, powering caching, session stores, leaderboards, queues, and analytics in thousands of systems. As […]
The Trino query engine is one of the most important pieces of infrastructure in the modern data stack. Many organisations […]
Apache NiFi has long been the backbone of enterprise data flow automation, enabling secure, scalable, and real-time data movement across […]
Name
Work Email*
What is 9 + 8 ?
Full Name*
Company Email Address*
Message*
What is 4 + 7 ?
Wish to ask us something? We're available across channels. Ping us anytime.
Email Address*
Contact Number*