

Apache Spark With Delta Lake Doing Wonders
Spark
5 MIN READ
June 1, 2022
![]()

When talking about big data processing with Apache spark, it is gaining steam in real-world adoption. Apache Spark is an open-source platform and has grown over the years. It has become one of the largest open-source big data processing/ streaming communities for more than 50 organizations.
Curious how Apache Spark helps any organization grow worldwide? Well! This data processing engine stands out best for its ability to process large volumes of data efficiently in less time. It chooses to have data persistence in memory on its processing framework.
Continue reading our blog to learn more on extensive data analysis with Apache Spark and its wonders with Delta Lake.
What Is Apache Spark, And How Does It Outcast Its competitors?
Apache spark is the most actively developed open source project in big data and is probably the most used. With hundreds of people contributing to its updates, new features/ capabilities are continuously added—for example, Spark’s Machine Learning Library and other different types of analytics.
The unique thing about Apache Spark is the software framework that combines both data and AI applications (Artificial Intelligence Applications). Hence with Apache Spark, one can do large scale data transformation and analysis while adding the art of machine learning.
Apache Spark offers a complete data processing platform that includes ETL (extracting, transforming, and loading data), SQL (Structured Query Language), and real-time data streaming.
- ETL enables you to collate data from several sources or output to one or many destinations.
- SQL helps in communication with the database.
- Spark Streaming allows quick processing of big data to extract real-time insights from it.
With in-built machine learning features, Apache Spark understands and builds methods that “learn” to improve performance on different sets of tasks. It allows applications deployed on Apache Spark to predict outcomes without being explicitly programmed to do the same.
- Fewer errors.
- Offers digital assistance.
- Time- effective.
Apache Spark can quickly deploy many highest-quality applications with a well-designed framework with the parallel processing system and AI.
Apache Spark Outcasting Mapreduce
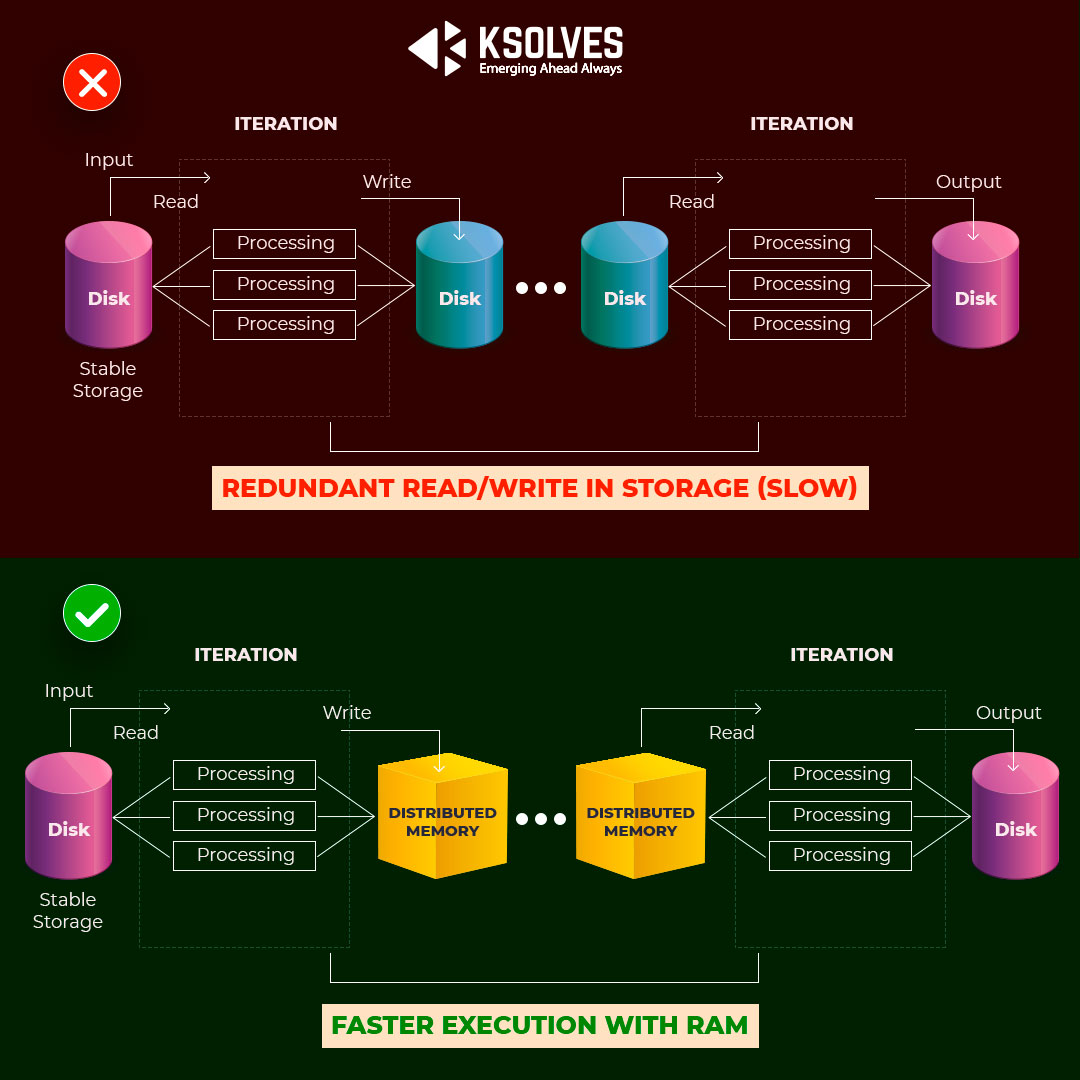
Both Apache Spark and Mapreduce frameworks process and generate big data. However, Apache Spark Streaming is significantly much faster than MapReduce. Data sharing in MapReduce is slow because of disk IO (Input Output). Apache works well on the problem by supporting in-memory processing computation rather than disk IO. Data sharing in memory is 10 to 100 times faster than any network or disk. Hence, 90% of the time consumed in HDFS (Hadoop Distributed File system) read/ write jobs in Mapreduce gets saved.
- Apache Spark supports in-memory processing computation using Resilient Distributed Datasets (RDD).
- Apache Spark stores Intermediate results (State of the JOB) in distributed memory (Random access memory). When RAM is not sufficient, it uses stable storage (Disk).
- Different queries run on the same data set repeatedly kept in RAM for better execution.
Making Apache Spark Better With Delta Lake
Are you wondering if Apache Spark has made big data processing quick and more accessible, then why do you need Delta Lake? Well! Spark is undoubtedly a powerful processing engine, but there are some areas where Spark is still struggling. However, if we combine Apache Spark with Delta Lake, it can overcome all those challenges.
Challenges To Overcome:
ACID(Atomicity-Consistency-Isolation-Durability) Compliance:
No ACID Compliance:
Atomicity:
As per the Spark Documentation, save modes(overwrite/ append) don’t lock any data (not Atomic). Also, Overwriting deletes the previous data stored.
- The lack of Atomic APIs creates fraudulent data during job failure.
- Old data gets deleted during the overwriting operation before new information is written. Hence, overwriting creates a situation of NO DATA available at a particular time.
Although Spark API (Application Programming Interface) internally performs job level commits. But, it only helps to achieve some degree of atomicity and these work with append mode.
Consistency:
During overwriting, it works in two states:
- When Spark Writer API deletes the old file from memory.
- When Spark Writer API places the new one in memory.
In- between, there is no data available. If in-between your job fails, you lose the data.
Isolation:
Suppose we are writing to a dataset which isn’t yet committed, and there is another concurrent processing on the same dataset (reading/ writing). As per isolation, one process shouldn’t impact the other. However, Spark has no such separation due to a lack of atomicity.
Durability:
Durability means that all the transactions we have committed should be permanently available. With Apache Spark, we can’t expect atomicity. Hence there is no isolation. And without isolation, we can’t restore all the transactions that are not committed during any disaster.
You must have noticed that all the ACID transactions are inter-connected. Due to a lack of atomicity, we lose consistency and isolation. Lack of isolation further makes us lose durability.
Quick summary
- There is a possibility of creating fraudulent/ missing data due to some exceptions.
- We need to wait if the same dataset is getting overwritten by another concurrent process.
- It doesn’t offer an UPDATE or DELETE option because of in-compliant ACID transactions with Spark.
Small File Processing:
If we need to work on many small files, there will be a negative impact on job execution time. Spark will spend most of its time opening and closing those files, which will slow down listing operation too.
Lack of Schema Enforcement
A schema is a collection of metadata describing the relationships between objects and information in a database. Spark implies Schema on read-only tasks and never validates it during a write operation.
An example to understand better:
Let us have a file with two records, both having integer values. Now we want to read a file > Write it into Apache Parquet format using overwrite mode > Read the parquet file back >Display the file. We can get all of this done without any error.
Now! Let us have a file again with two records, one with integer values but the other with decimal values. We use the same program to read the file, write it into Apache Parquet and read it back and display it. However, instead of writing it into Parquet format using overwrite mode, we choose to write it into Parquet format using append mode.
Our program will read the file, write it into Parquet format and read the parquet file back without exception. But, the moment we want to display the data frame, it shows an error “Unsupported”.
It is happening because when one of the records changes the values from Integer to decimal, Spark writes data without any issue. However, when it reads the appended data and calls an action, it throws an error due to incompatibility to Schema during a write operation.
Delta Lake and Apache Spark Together Makes A Better Fit
You can overcome all of the challenges mentioned earlier by plugging Delta Lake with Spark. Delta Lake for Apache Spark works as an additional service and does wonders. Here is a sneak peek about Delta Lake and how it makes Spark Better!
Delta Lake provides an open, reliable, performant, and secure foundation for Data Lake use (storing and managing all of your data). It supports analytics, and AI use cases.
- It is based on Parquet.
- It offers Data Lake reliability of ACID transactions from traditional data houses on Data Lake architecture.
- Unifies batch and streaming data processing.
Delta Lake has been designed to be 100% compatible with Apache Spark. It is easy to convert your existing data pipelines to begin using a Data Lake with minimal changes to your Spark code.
Spark With Delta Lake Inherits ACID Properties:
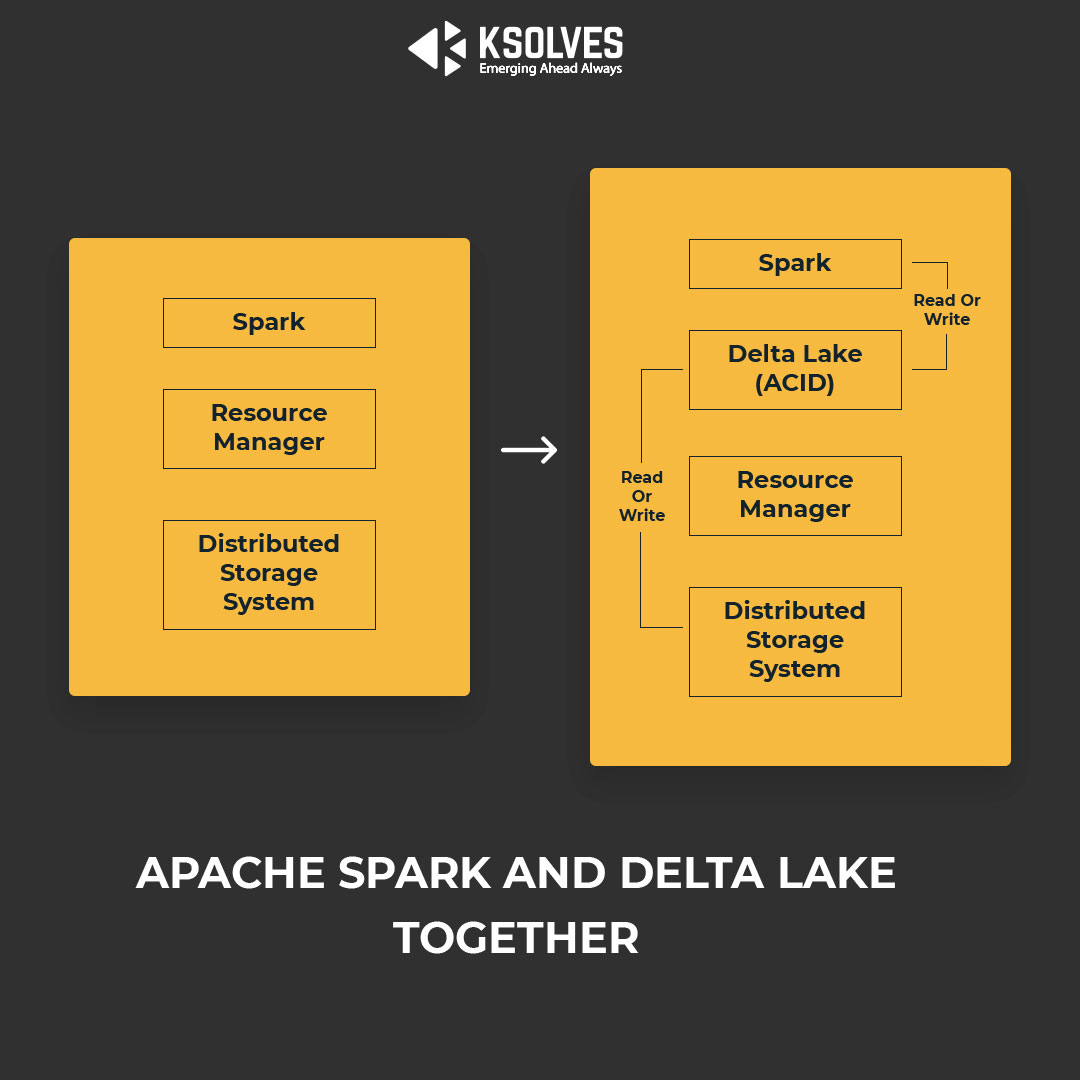
Spark uses distributions like Amazon S3 and Azure Blob to store data (read/ write) without atomicity. However, when plugged in with Delta Lake (well benefited with ACID transactions), Spark talks to Delta Lake, which further talks to underlying distributed storage systems. It lets Spark inherit all the ACID transaction properties of the Delta Lake.
Spark With Delta Lake Now Enables Update and Delete:
Spark doesn’t allow you to run update and delete statements but integrating it with Delta Lake makes it easy.
- Read data.
- Save as Delta Table.
- You can Update Records.
- You can Delete Records.
Solving Small Files Issue Using Apache Spark And Delta Lake
Spark with Delta Lake accumulates many small files, especially when these small files are incrementally updated. It uses a Compaction algorithm to merge small files into larger ones. It saves time. Hence, it keeps reading fast.
Apache Spark With Delta Lake getting Schema Enforcement:
Let us consider the same data file with decimal values as discussed above. Spark with Delta Lake Schema Enforcement will now work efficiently:
- It reads the data.
- Delta Lake will enable Apache Spark for schema validation on write. It will throw a message “failed to merge incompatible data types” and discards the transaction. Hence, Delta Lake validates the Schema right before writing.
- It helps track the issues in the beginning. It doesn’t mix with good data, making it easy to discover the root cause.
- It helps to validate the same column data types as the target table.
- The number and names of columns are the same as a target table.
Conclusion
Apache Spark has the best abilities for processing streaming data. Integrating Delta Lake with Apache Spark solves unfixed loopholes to process complex data effectively. If your business too wants to leverage the reliability of Delta Lake on Apache Spark but lacks expert guidance, Ksolves is here to help. Turn all your dreams into reality by Ksolves Apache Spark Support.
Ksolves is a leading firm specializing in providing a wide variety of services to businesses of all sizes, from start-ups to small and big businesses. Our Apache Spark services will help you enhance your business’s efficiency. We are sure about our words as we have a team of highly skilled professionals specializing in all of Apache Spark’s aspects.
Contact us at sales@ksolves.com. You can also directly call us on +91 8130704295.
FAQ
Why Combine Spark With Delta Lake?
Delta Lake is a free open source storage layer that provides better data reliability technologies to Data Lakes. It provides the ACID transactions, unifies streaming, scalable metadata handling, and batch data processing.
How Is Delta Lake Related To Apache Spark?
Delta Lake rests on top of the Apache Spark. The format assists in simplifying building the big data pipelines and increasing the efficiency of the pipelines.
Is It Possible To Stream Data Directly Into And From Delta Tables?
Yes! Use structured streaming to write data into Delta tables directly.
![]()















AUTHOR
Spark
Atul Khanduri, a seasoned Associate Technical Head at Ksolves India Ltd., has 12+ years of expertise in Big Data, Data Engineering, and DevOps. Skilled in Java, Python, Kubernetes, and cloud platforms (AWS, Azure, GCP), he specializes in scalable data solutions and enterprise architectures.
Share with