
Computer Vision Guide
Summary
Computer vision, a rapidly evolving AI field, enables machines to interpret and act on visual data from images and videos. Leveraging techniques from deep learning, transformers, and classical methods, it automates tasks like inspection, recognition, monitoring, and analytics. Businesses across retail, healthcare, manufacturing, and logistics benefit from improved efficiency, accuracy, and decision-making. Ksolves Computer Vision Services offer end-to-end solutions, from model development to deployment, helping organizations unlock actionable insights, optimize operations, and drive innovation through intelligent visual data analysis.
1. Introduction
Computer Vision is one of the most exciting and rapidly evolving areas of artificial intelligence (AI). Simply put, it enables machines (computers, robots, embedded systems) to “see,” interpret, and make decisions based on visual inputs, such as images or video frames. It draws on disciplines including signal processing, pattern recognition, machine learning, optimization, geometry, and neuroscience of human vision.
As cameras, sensors, and computing become cheaper and more powerful, visual data is proliferating everywhere, from mobile phones to surveillance cameras, drones, and autonomous vehicles. Computer Vision unlocks the value in this deluge of visual data by automating tasks that humans previously performed, such as inspection, recognition, navigation, and monitoring.
In the rest of this guide, we’ll delve deeply into how computer vision works, what is possible, what remains hard, and how to build real systems.
2. Fundamentals of Computer Vision
2.1 What Is Computer Vision?
At its core, computer vision is about the automated extraction of meaningful information from images or video. That information could be:
- A label (this image is a “cat”)
- The position and size of an object (a bounding box)
- A segmentation mask delineating the object’s precise shape
- The 3D structure of a scene (depth map, point cloud)
- Motion over frames (optical flow, trajectories)
- Text inside images (OCR)
- A combination: e.g., “Person A is walking with object B, facing toward the camera, in corridor 3.”
Computer vision seeks to mimic (or even surpass) human visual inference, not just “seeing pixels,” but interpreting them semantically, understanding context, reasoning, and making decisions.
A more modern description emphasizes that computer vision is a subdomain of AI/ML focused on interpreting visual data (images, video) using algorithms, particularly leveraging deep learning and neural networks to move from low-level features to high-level semantic understanding.
2.2 History and Evolution
Understanding how we arrived at this point helps us appreciate both our limitations and future directions.
- The origins trace to neurology: in the 1950s–60s, researchers like Hubel and Wiesel studied how visual cortex neurons respond to lines, edges, orientations, inspiring computational models.
- Early work in digital image processing (scanning, filtering, edge detection) in the 1960s and ’70s laid the foundation.
- In 1974, optical character recognition (OCR) systems were capable of recognizing printed text.
- In the 1980s and 1990s, more advanced pattern recognition, template matching, and early neural architectures were explored.
- In 2010, the release of ImageNet (millions of labeled images across thousands of classes) catalyzed progress.
- In 2012, AlexNet, a deep CNN, dramatically reduced classification error and ignited the deep learning revolution in computer vision.
- Since then, increasingly sophisticated CNNs, region-based detectors, segmentation networks, and, more recently, transformer-based models have pushed boundaries.
Today, computer vision is mainstream in many products and domains.
3. Core Techniques & Algorithms
This section dives into the building blocks of computer vision, both classical and modern.
3.1 Image Preprocessing
Vision inputs often need cleaning or normalization:
- Color space conversion: RGB → grayscale, HSV, YCbCr, etc.
- Histogram equalization/contrast enhancement
- Denoising/smoothing (Gaussian blur, median filter)
- Edge enhancement/sharpening
- Geometric transformation: resizing, cropping, rotation, warping
- Gamma correction/normalization
- Lens distortion correction/camera calibration
- Image alignment / registration (especially for multi-view or time-sequence data)
Preprocessing helps standardize inputs for downstream models.
3.2 Feature Extraction & Representations
Before the advent of deep learning, much vision was based on carefully designed features. Even now, features are still necessary (or implicitly learned). Some key ideas:
- Edge detection (Sobel, Canny)
- Corner / interest point detection (Harris corner, Shi–Tomasi)
- Keypoint descriptors: SIFT, SURF, ORB, BRISK
- Histogram of Oriented Gradients (HOG)
- Local binary patterns (LBP), texture descriptors
- Color histograms, color moments
- Scale-invariant and rotation-invariant features
- Bag-of-visual-words methods
- Feature pyramids / multi-scale representations
- Feature embeddings, learned via CNNs or other deep nets
These features aim to capture patterns that are robust to noise, lighting changes, and small transformations.
3.3 Classic (Pre-Deep Learning) Methods
Before deep learning domination, the following methods were widely used:
- Template matching
- Sliding-window classifiers (e.g., using SVMs on HOG features)
- Deformable part models (DPMs)
- Graphical models and Markov random fields (e.g., for segmentation)
- Active contours/snakes, level sets
- Watershed segmentation
- Optical flow (e.g., Lucas Kanade, Horn–Schunck)
- Structure from motion, stereo vision, disparity estimation
These models captured geometric constraints and prior knowledge, but often lacked flexibility and generalization.
3.4 Deep Learning Methods
Deep learning has revolutionized computer vision by enabling end-to-end learning from pixels to predictions. Key points:
- Convolutional Neural Networks (CNNs): building blocks like convolution, pooling, normalization, residual connections, etc.
- Backpropagation and gradient-based optimization
- Common architectures: LeNet, VGG, ResNet, Inception, DenseNet, EfficientNet
- Region-based networks: R-CNN, Fast R-CNN, Faster R-CNN
- One-stage detectors: YOLO, SSD, RetinaNet
- Segmentation networks: FCN, U-Net, DeepLab, Mask R-CNN
- Encoder–decoder architectures
- Multi-scale and feature pyramid networks (FPN)
- Generative models: variational autoencoders (VAEs), GANs, diffusion models for vision
- Siamese networks, metric learning for similarity/verification tasks
- Contrastive learning, representation learning
In practice, deep learning does not fully replace classical computer vision. Real-world pipelines often combine deep models with classical techniques for preprocessing, geometric reasoning, post-processing, and rule-based validation to achieve robust and efficient production systems.
Deep models learn hierarchical representations, from edges to textures to object parts to semantics, all automatically from data.
Integration of attention mechanisms and transformer architectures is a more recent shift (see next section).
Also Read: Top 10 Deep Learning Algorithms That You Must Know
3.5 Attention, Transformers, and Recent Advances
Recent vision models increasingly use attention and transformer techniques:
- Vision Transformers (ViT): Images are split into patches, embedded, and processed using standard Transformer blocks
- Hybrid architectures: CNN + Transformer models combine local feature extraction with global context modeling
- Attention mechanisms: Spatial, channel, and temporal attention help models focus dynamically on relevant regions and features
Vision foundation models are large, pre-trained models designed to adapt across multiple vision tasks such as classification, detection, retrieval, and captioning. In practice, these models typically require task-specific fine-tuning, prompting, or adapter-based customization to achieve production-level performance. For example, models like Florence serve as flexible foundations rather than turnkey solutions.
Hybrid and physics-inspired approaches integrate domain priors such as optics, geometry, and physical constraints with deep learning. For instance, the PhyCV library applies physics-based principles to vision tasks.
Together, these advances move computer vision toward more general, adaptable, and efficient systems while retaining the need for task- and domain-specific optimization.
4. Practical Business Applications of Computer Vision
Computer vision is no longer a research curiosity; it’s driving real-world business value. Below are key applications:
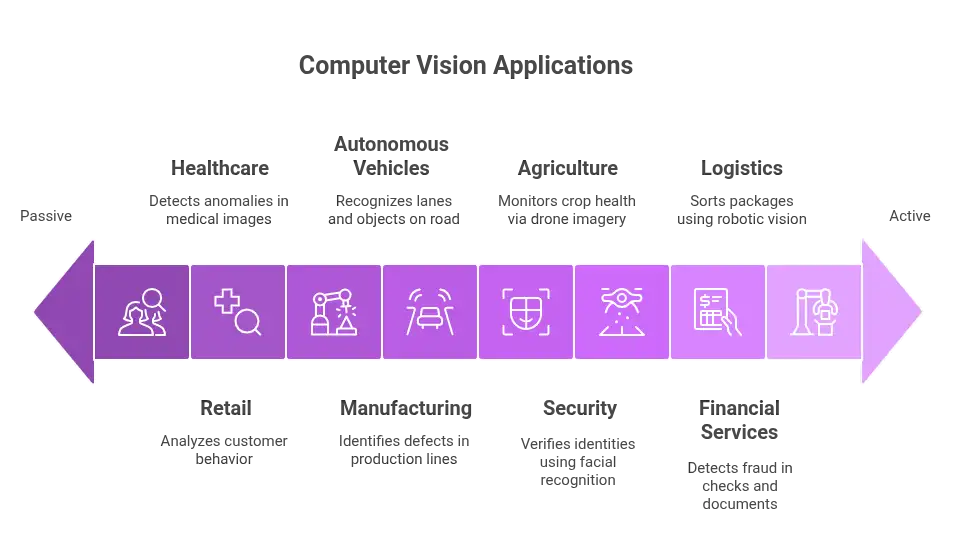
4.1 Retail and E-commerce
- Automated inventory monitoring
- Customer behavior analysis via heatmaps
- Visual search and recommendation engines
- Fraud detection and counterfeit identification
4.2 Healthcare
- Medical imaging diagnostics (X-rays, MRIs, CT scans)
- Automated anomaly detection (tumors, fractures)
- Patient monitoring and fall detection
- Workflow automation in radiology labs
4.3 Manufacturing
- Automated quality inspection
- Defect detection in production lines
- Robotics-assisted assembly
- Predictive maintenance using visual anomaly detection
4.4 Autonomous Vehicles
- Lane and object detection
- Traffic sign recognition
- Pedestrian and cyclist detection
- Sensor fusion with LiDAR and radar
4.5 Security and Surveillance
- Facial recognition and identity verification
- Intrusion detection and activity recognition
- Behavior analysis for crowd safety
4.6 Agriculture
- Crop monitoring via drone imagery
- Disease detection in plants
- Automated harvesting using robotic vision
4.7 Financial Services
- Fraud detection in checks and documents
- Automated verification for KYC compliance
- ATM surveillance and transaction monitoring
4.8 Logistics and Supply Chain
- Package recognition and sorting
- Warehouse automation with robotic vision
- Real-time inventory tracking
5. Implementation Strategy for Businesses
5.1 Define Objectives
- Identify the business problem, such as quality inspection, security, analytics, etc.
- Determine KPIs: accuracy, speed, cost reduction, revenue impact
5.2 Data Collection & Management
- Collect diverse and representative datasets
- Ensure high-quality labeling and annotation
- Address data privacy and compliance
5.3 Model Selection & Training
- Classical methods for lightweight, explainable solutions
- Deep learning models for complex or high-volume tasks
- Pre-trained models and transfer learning to reduce development time
5.4 Integration & Deployment
- Edge devices for low-latency applications
- Cloud platforms for scalable processing
- APIs for seamless integration with existing software
5.5 Monitoring & Maintenance
- Continuous monitoring for drift and performance degradation
- Periodic retraining with new data
- Robust evaluation against real-world conditions
6. Challenges and Limitations
- Data dependency: Computer vision systems require large volumes of high-quality, well-annotated visual data, which is expensive to collect and label.
- Generalization: Models often degrade under domain shifts such as lighting changes, occlusion, camera angle variations, or unseen environments.
- Interpretability: Deep vision models lack transparency, making it difficult to explain or validate visual decisions in safety-critical applications.
- Computational demands: Training and deploying vision models require significant GPU/edge hardware resources, impacting cost and latency.
- Ethical risks: Vision systems raise concerns around biometric bias, facial recognition errors, surveillance misuse, and unfair profiling.
- Privacy and compliance: Visual data frequently contains sensitive personal information, requiring dataset consent management and adherence to regulations in healthcare, finance, and security domains.
7. Future of Computer Vision in Business
- AI-powered analytics: Automating insights from video and images
- Augmented Reality & Metaverse: Real-time scene understanding
- Robotics and automation: Collaborative AI systems in factories and warehouses
- Vision foundation models: Pre-trained models adaptable to multiple tasks
- Sustainability: Reducing waste and energy use through visual monitoring
8. How Ksolves Can Help with Computer Vision Services
At Ksolves, we provide end-to-end Computer Vision Services that help businesses unlock the full potential of visual data. Our offerings include:
- Custom model development for specific business needs
- Image and video analytics for operations and security
- Real-time object detection and tracking
- Integration with AI, IoT, and robotic systems
- Scalable deployment on cloud or edge devices
What Makes Ksolves a Trusted Computer Vision Partner

- Production-First Vision Architecture: Solutions are designed for real-world conditions, handling lighting variation, camera drift, occlusions, and noisy visual inputs without compromising accuracy.
- Hybrid Computer Vision Pipelines: An intelligent combination of deep learning models, classical vision techniques, and rule-based validation ensures robustness and explainability in enterprise deployments.
- Strong Data & Annotation Strategy: Focus on dataset quality, labeling consistency, and bias reduction to improve model reliability and long-term performance.
- Scalable Cloud and Edge Enablement: Optimized deployments across cloud, edge devices, and embedded systems to support real-time and high-volume visual analytics.
- Continuous Monitoring & Model Governance: Built-in performance tracking, drift detection, and retraining workflows to maintain accuracy post-deployment.
- Security, Privacy, and Compliance Ready: Designed with data protection, auditability, and regulatory alignment for healthcare, finance, and surveillance use cases.
Accelerate your AI transformation today. Partner with Ksolves for advanced Computer Vision Services to automate, optimize, and innovate.
Also Read: Top Computer Vision Consulting Mistakes That Can Sink Your Project
9. Conclusion
Computer vision is transforming the way businesses operate across various industries by automating visual tasks, enhancing decision-making, and unlocking new revenue opportunities. From retail and healthcare to manufacturing and autonomous systems, the applications are vast and impactful. By leveraging modern techniques, deep learning, transformers, attention mechanisms, and vision foundation models, organizations can implement robust, scalable solutions. Partnering with experts like Ksolves ensures that businesses harness the full power of computer vision efficiently, securely, and strategically.
FAQs
Q1. What is computer vision?
Computer vision is an AI field that enables machines to interpret and act upon visual information from images or video.
Q2. How can computer vision benefit my business?
It automates tasks like inspection, surveillance, analytics, and quality control, improving efficiency, accuracy, and decision-making. Click here to know in detail.
Q3. Do I need a large dataset for computer vision?
High-quality labeled data is essential, but transfer learning and pre-trained models can reduce data requirements.
Q4. Why Choose Ksolves for Computer Vision Services?
Ksolves offers end-to-end services from model development to deployment, ensuring scalable, secure, and tailored AI solutions.











