

SAI in Cassandra 5.x: A New Indexing Era
Apache Cassandra
5 MIN READ
February 10, 2026
![]()

In distributed, wide-column NoSQL databases, query flexibility has traditionally come at the cost of performance and efficiency. Data models were often designed around strict access patterns, leaving little room for ad hoc querying without creating additional tables or compromising scalability.
With Apache Cassandra 5.x, the introduction of Storage-Attached Indexes (SAI) fundamentally shifts this paradigm. SAI enables efficient secondary indexing directly at the storage layer, allowing developers and architects to design more adaptable data models while preserving Cassandra’s hallmark performance, scalability, and storage efficiency.
In this blog, we will discuss
- what SAI is and why it matters.
- Highlight ROI: faster queries, lower storage, simpler models.
- Compare traditional vs. SAI-enabled data models.
- Share best practices and common pitfalls.
- Provide recommendations for production use.
What is Storage Attached Indexing (SAI)?
Storage-Attached Indexing (SAI) is a modern indexing feature in Apache Cassandra 5.x that makes it easier to query data without redesigning your entire schema. Instead of relying on external or coordinator-heavy indexes, SAI is built directly into Cassandra’s storage layer.
Each node maintains indexes for the data it owns, allowing queries to run locally and efficiently across the cluster. This design keeps Cassandra’s distributed nature intact while delivering faster and more flexible query performance. In simple terms, SAI lets you ask more questions of your data without giving up scalability, speed, or reliability.
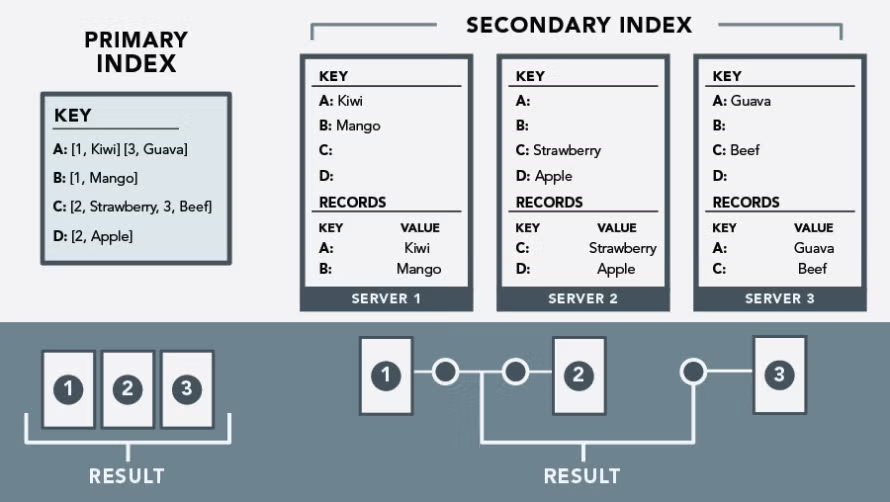
Challenges with Traditional Indexing in Cassandra
In earlier versions of Cassandra (pre-5.0), secondary indexes (2i) or the older SASI had various limitations:
- Poor scalability when indexing many rows / many columns
- High storage overhead for index data
- Query limitations (e.g., you’d often need to design around partition keys, or maintain separate tables for different query patterns)
- Performance trade-offs: full cluster scans, unpredictable latency
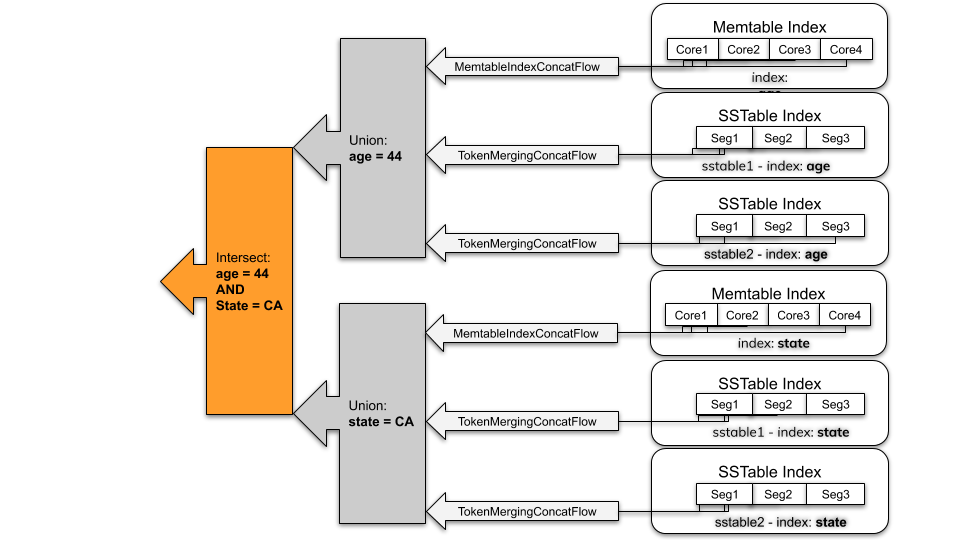
The solution: SAI in Cassandra 5.x
With Cassandra 5.x, the SAI feature fundamentally changes indexing by embedding index data closely with the storage engine’s memtables & SSTables. As per the official docs: Storage-attached indexing (SAI) adds column-level indexes to any CQL table column of almost any CQL data type.
Key Benefits
- It shares common index data across multiple indexes on the same table
- Lower disk usage compared to legacy secondary indexes
- Excellent performance for numeric range queries, even at scale
- Fully integrates with the Cassandra storage engine (memtables + SSTables), thereby lowering operational complexity.
In short, SAI delivers the query flexibility developers always wanted, without the scalability and performance penalties of older index methods.
Why the ROI Matters: Performance, Storage, Modeling
The real value of Storage-Attached Indexing (SAI) lies in its measurable return on investment. From faster query execution to reduced storage overhead and simpler data models, SAI delivers benefits that directly impact both engineering efficiency and operational costs. Let’s break down the tangible ROI of SAI from faster queries to learner storage and simpler modeling.
Performance Gains
- Because SAI builds the index during the memtable/SSTable lifecycle rather than as an afterthought, queries are faster and more efficient.
- The documentation says, “SAI outperforms any other indexing method available for Apache Cassandra.”
- You’ll see fewer full-cluster scans when you query on non-primary key columns, reducing latency and resource consumption.
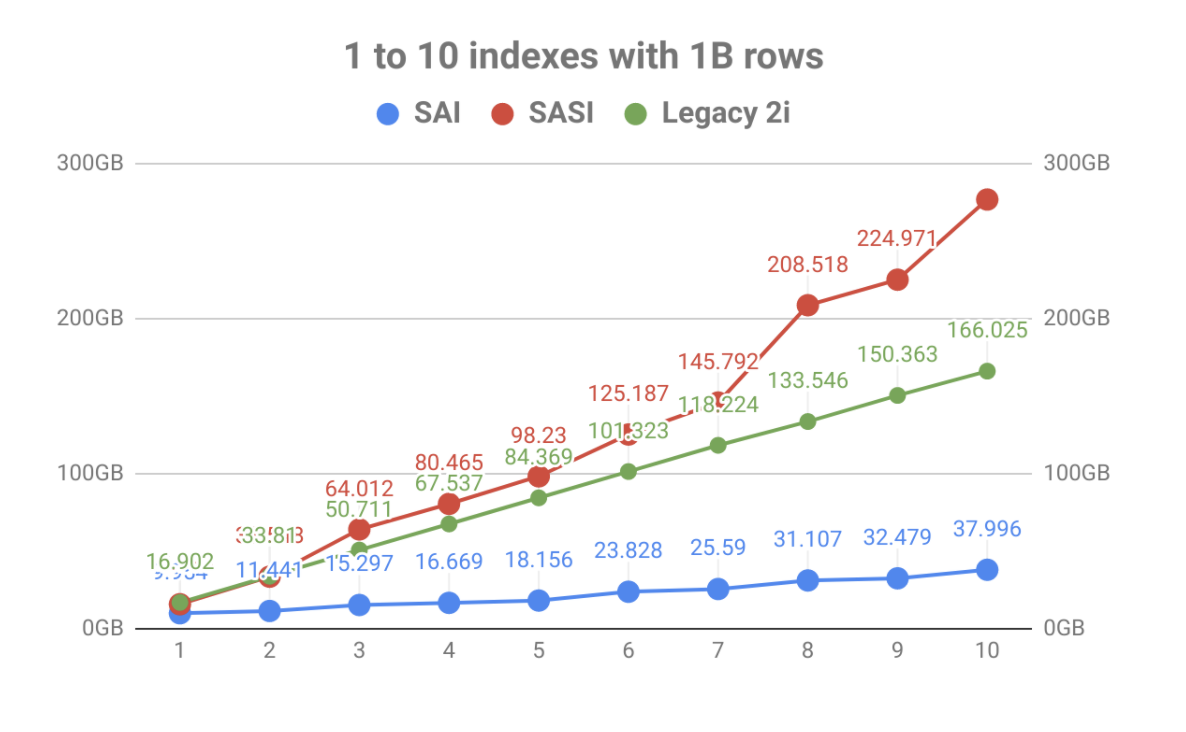
Storage Efficiency
- Traditional indexes often duplicate data or require extra tables for different query patterns; SAI reduces that overhead.
- For example, SAI shares common index data across multiple indexes on the same table, so adding more indexed columns doesn’t linearly increase storage footprint.
- Lower storage means lower infrastructure costs (disk, I/O, backup/restore overhead) and simplified operations.
Better Data Modeling Flexibility
- One of the biggest wins: you can model tables more naturally (for your business domain) and rely on SAI for query flexibility rather than only designing for access patterns. As one blog puts it:
- This reduces the need for duplication of tables, maintaining multiple denormalized versions, or building complex routing layers just for query access patterns, which in turn lowers development time, reduces the risk of bugs, and simplifies maintenance.
Summary of ROI
| Benefit | Impact |
| Faster queries on non-PK columns | Better user experience, lower latency, less CPU/I/O load |
| Less storage overhead for indexes | Lower TCO for disks/IOPS/backup/restore |
| Simpler modeling & fewer tables | Less development/maintenance overhead, fewer failure points |
| Easier operations (streaming, bootstrap, compaction) | Improved operational resilience, fewer surprises |
Comparing “Traditional” Data Modeling vs SAI-Enabled
To understand the impact of Storage-Attached Indexing (SAI), let’s walk through a practical comparison. This section highlights how data modeling strategies differ before and after SAI, using a common real-world query scenario. We will focus on schema design, query flexibility, and operational complexity.
Traditional model (before SAI)
Scenario: Suppose you have a table of users and you want to query by country, age, and email frequently—not just by the partition key (user_id).
Typical modeling approach:
- You might design a table with PRIMARY KEY (user_id) for writes.
- But for queries like WHERE country=’IN’ AND age>30, you would either:
- Use a secondary index (2i)—often with poor performance at scale.
- Or duplicate the data into a table with PRIMARY KEY ((country), age, user_id), etc., to serve that query pattern.
- This means maintaining multiple tables, more writes, and more complexity.
Example code snippet:
CREATE TABLE users (
user_id uuid PRIMARY KEY,
email text,
country text,
age int,
signup_date timestamp
);
Then, for the query: SELECT * FROM users WHERE country=’IN’ AND age>30, you might create a secondary index on country or age, but historically, performance suffers, or you hit full node scans.
SAI-Enabled model (Cassandra 5.x)
With SAI, you can achieve the same query flexibility without redesigning your tables purely for access patterns.
How:
- Keep your table design natural:
CREATE TABLE users ( user_id uuid PRIMARY KEY, email text, country text, age int, signup_date timestamp );
-
Create SAI indexes on the non-PK columns you need:
CREATE INDEX country_sai_idx ON users (country) USING 'sai' WITH OPTIONS = {'case_sensitive': 'false', 'normalize': 'true', 'ascii': 'true'};CREATE INDEX age_sai_idx ON users (age) USING 'sai';
- Now you can freely query:
SELECT * FROM users WHERE country = 'IN' AND age > 30;
Benefits of Data Modeling:
- Fewer tables to manage, reducing schema sprawl and operational overhead
- Minimal write-side duplication, lowering storage costs and write amplification
- Simpler, more expressive queries, without redesigning schemas for every access pattern
- Domain-driven data models, organized around business entities (users, events, orders) rather than rigid query-specific tables
Data Modeling Best Practices with SAI
To get the most out of SAI, follow these guidelines.
Things to do
- Identify non-PK columns used in WHERE filters—these are candidates for SAI indexes.
- Use SAI for queries that previously forced table duplication—convert those into index usage instead.
- Combine SAI with the correct primary key/clustering when needed—modelling is not completely free-form.
- Monitor index size & query performance—though SAI uses less storage, you should still observe behavior.
- Leverage new data types—Cassandra 5.x supports vector types and ANN search when combined with SAI.
Things to avoid / trade-offs
While Storage-Attached Indexing (SAI) offers significant advantages, it is important to understand its limitations and trade-offs before adopting it broadly.
- SAI cannot be created on partition key columns, as indexing them would be redundant and provide no performance benefit.
- While SAI supports a wide range of query patterns, it is not a full-featured search engine; advanced text search or full-text indexing use cases may still require external solutions.
- Altering an existing SAI index is not supported; any changes require the index to be dropped and recreated.
- Keep in mind that creating multiple indexes is not free—each indexed column adds write-time overhead, which can impact ingestion performance if not planned carefully.
- Thorough testing is essential, especially for wide partitions or high-throughput workloads, to ensure SAI performs efficiently under real-world conditions.
Understanding these considerations helps teams apply SAI where it delivers the most value—without introducing unnecessary complexity or performance risk.
When SAI Changes Your Data Modelling Approach
Here are three concrete “shift” scenarios where SAI enables you to rethink your modelling.
1. Simplified many-to-many / search by attribute
Previously, supporting diverse query patterns required maintaining separate tables or manually managing inverted indexes.
With SAI, you can index attributes directly and query them from the same table, simplifying both schema design and query execution.
2. Fewer query-specific tables
Previously, for each query pattern, you’d spin up a tailored table with different PK/clustering.
With SAI, you can maintain far fewer tables and rely on indexes to handle query variations more efficiently.
3. Better modelling for evolving requirements
Previously, if new query requirements came up, you’d rework the schema or add tables.
With SAI, you can add an index (on a new column) rather than a full schema redesign.
Wrapping Up
Storage-Attached Indexing (SAI) in Apache Cassandra 5.x is a game-changer for data modeling. It enables efficient indexing on non–primary key columns, delivering faster queries, lower storage overhead, and simplified, more adaptable schemas. Many designs built around the limitations of legacy secondary indexes can now be streamlined, reducing the need for query-specific tables or heavy denormalization. While SAI enhances flexibility, it’s not a silver bullet—teams should test workloads, understand trade-offs, and follow best practices for index management.
Bottom line: For greater query flexibility without constant schema redesigns, SAI should be central to your Cassandra 5.x strategy.
If you want to upgrade your Cassandra version to 5.x or plan to modernize your data architecture, Ksolves can help you assess your existing models, design SAI-optimized schemas, and ensure a smooth, performance-driven migration. Connect with Ksolves Cassandra experts to make the most of Cassandra 5.x with confidence.
![]()

Apache Flink is the backbone of real-time data pipelines across financial services, e-commerce, IoT, and logistics. But as the state […]


Redis earns its reputation as one of the fastest data stores available, but raw speed at the engine level does […]












AUTHOR
Apache Cassandra
Anil Kushwaha, Technology Head at Ksolves, is an expert in Big Data. With over 11 years at Ksolves, he has been pivotal in driving innovative, high-volume data solutions with technologies like Nifi, Cassandra, Spark, Hadoop, etc. Passionate about advancing tech, he ensures smooth data warehousing for client success through tailored, cutting-edge strategies.
Share with