

Project Name
Enterprise Data Lakehouse and NLP Search Platform for a UAE Lighting & Distribution Company
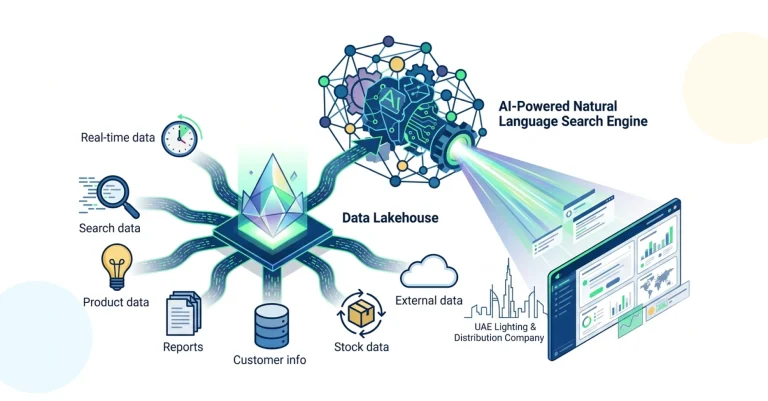
![]()
A UAE-based lighting technology and distribution company, operating under the Alrouf brand across retail, commercial, and project channels in the Gulf region, ran its business across seven disconnected systems: Salesforce for CRM, Odoo for ERP, Microsoft Outlook and Teams for communication, WhatsApp for field sales, MailChimp for marketing, and DoubleClick as its legacy ERP source mid-migration.
With no integration layer connecting any of them, answering a question like “What are our top five customers by margin this quarter?” meant hours of manual extraction across four systems and a spreadsheet to stitch it together. The company engaged Ksolves to fix this at the foundation: a governed Data Lakehouse consolidating all seven sources, paired with an LLM-powered natural language search engine that lets any business user query the full enterprise data estate by typing a plain-language question, a core capability of Ksolves’ Big Data services.
- 7-System Data Fragmentation: Business data was siloed across Salesforce, Odoo, Microsoft Outlook, Microsoft Teams, WhatsApp, and MailChimp with no integration layer, no shared data model, and no platform where cross-functional questions could be answered without manually pulling from multiple tools.
- Manual Reporting Consuming Operational Time: Generating reports on quote win rates, customer margin, inventory vs. pipeline, or campaign performance required staff to extract data from several systems, reconcile inconsistencies, and consolidate in Excel, a process that was slow, error-prone, and dependent on individual knowledge of each source system.
- No AI Layer to Support Quoting and Pricing: Sales teams had no visibility into historical win rates, margin trends, or demand forecasts at the point of quote creation. Pricing was done manually, without data, causing inconsistencies, missed margin opportunities, and slow turnaround on proposals.
- Legacy ERP Mid-Migration with Dual-Source Complexity: The company had recently migrated from DoubleClick to Odoo, requiring the data platform to manage a clean source switchover: ingesting from DoubleClick as the historic source while transitioning live data flows to Odoo, without disrupting the Lakehouse or requiring architectural rework.
- Unstructured Data Untapped: A significant volume of business context existed in unstructured formats: email threads in Outlook, conversations in Teams and WhatsApp, and campaign data in MailChimp. None of it was accessible for search or analysis, leaving customer intent and sales intelligence invisible to the business.
- No Natural Language Interface for Business Users: Non-technical users had no way to query enterprise data without IT involvement or SQL knowledge. Data-driven decision-making was restricted to a small number of analysts rather than available across sales, operations, and leadership.
Ksolves architected and delivered the full AI Factory end-to-end: a production-grade Data Lakehouse as the governed data foundation, with an LLM-powered natural language search engine on top as the interface for the entire business. The governing design principle was open-source first and cloud-neutral, every component, from Apache NiFi for ingestion to Apache Iceberg for table format to the LLM layer for search, was selected to avoid vendor lock-in while delivering enterprise-grade reliability and security.
- Data Lakehouse Foundation (Apache NiFi + Kafka + AWS S3 + Apache Iceberg): Automated ingestion pipelines were built for the initial three sources: Salesforce (CRM records, leads, opportunities), Microsoft Outlook (email threads and attachments), and DoubleClick ERP (CSV uploads). Apache NiFi handled visual flow orchestration; Apache Kafka provided real-time event streaming and buffering; AWS S3 served as the raw and processed object store; Apache Iceberg was deployed as the open table format unifying structured and unstructured data in a single governed Lakehouse, with TLS/SSL encryption in transit and AES-256 at rest.
- Source Expansion to Seven Connected Systems: Four additional sources were integrated, expanding the Lakehouse to the full operational footprint. Apache Spark and dbt handled transformation, enrichment, and indexing. Custom ingestion scripts were developed for WhatsApp and email APIs where standard connectors were insufficient.
- AI-Powered Natural Language Search Engine (LLM + RAG + NLP): The AI search layer used Large Language Models combined with Retrieval-Augmented Generation to enable contextual natural language queries across all seven sources. Users could ask "Show me the top 5 customers by margin this quarter" or "What were the last 10 interactions with this account?" and receive accurate, sourced answers without writing SQL or navigating multiple systems. The NLP layer handled query understanding, entity resolution, and response generation with citations to source data.
- Smart Quotation Engine: As the first tangible AI use case, a Smart Quotation Engine was delivered: integrating product catalogue, pricing history, customer win rates, and pipeline data from the Lakehouse to generate margin-aware quotes automatically, eliminating the pricing inconsistencies that resulted from manual cross-system data assembly.
- React/Node.js Web Application with Secure Access: A chat-like web interface was built on ReactJS and Node.js with PostgreSQL for application state. Authentication used username and password with TLS-secured access. A dedicated QA/Dev environment mirrored the production deployment for consistent testing and release management.
- Grafana Monitoring and Pipeline Observability: A full observability stack was deployed covering ingestion success rates, data freshness, processing latency, and system health across all seven source connectors, with alerting for pipeline failures or data quality degradation.
Technology Stack
| Component | Technology |
|---|---|
| Data Ingestion | Apache NiFi + Apache Kafka |
| Lakehouse Storage | AWS S3 + Apache Iceberg |
| Data Processing | Apache Spark + dbt |
| AI / Search Layer | LLM + RAG + NLP |
| Application | ReactJS + Node.js + PostgreSQL |
| Observability + Security | Grafana + VPC/Subnet Isolation |
- 7 Sources, 98.6% Pipeline Reliability: All seven sources (Salesforce, DoubleClick ERP, Odoo, Microsoft Outlook, Teams, WhatsApp, and MailChimp) are now ingested into a single Apache Iceberg Lakehouse on AWS S3, with Grafana-monitored pipelines sustaining a 98.6% ingestion success rate across all connectors. The business has clean, enriched, and traceable data across structured and unstructured content for the first time.
- 63% Reduction in Quotation Cycle Time via the Smart Quotation Engine: What previously required a sales rep to pull pricing history, product availability, and customer context from three or four systems manually now takes seconds. The Smart Quotation Engine generates margin-aware quotes directly from unified Lakehouse data, cutting average quotation cycle time by 63% and removing the pricing inconsistencies that came with manual multi-system assembly.
- 74% Reduction in Per-Report Effort Across Sales, Ops, and Marketing: Cross-functional reports on sales performance, campaign ROI, and operational KPIs that previously consumed an average of 3–4 hours per cycle in manual extraction and Excel consolidation are now served through the AI search engine in under 10 minutes, reducing per-report effort by 74% and removing analyst dependency for routine business questions.
- Data Access Expanded from 3 Analysts to the Full Business User Base: Before deployment, cross-system data queries were limited to the small number of staff with access to all source systems and the SQL knowledge to use them. The conversational search interface now gives every user in sales, operations, and leadership direct query access across all 7 connected systems, with accurate, source-cited answers returned in seconds, no SQL, no IT ticket.
- 100% Historical Data Continuity Across the DoubleClick-to-Odoo ERP Migration: With the company mid-migration between ERP systems, the Lakehouse was designed to ingest DoubleClick as the historic source and transition live data flows to Odoo post-migration. The switchover completed with zero Lakehouse downtime and 100% historical data continuity, preserving over 18 months of ERP records without architectural rework.

“For the first time, our sales and operations teams can ask questions about our business and get answers immediately, without waiting for a report or involving IT. The AI search engine has changed how we make decisions day to day.”
– Chief Digital Officer, UAE-Based Lighting and Distribution Company
Alrouf entered this engagement with seven data systems that could not talk to each other and a quoting process built on manual spreadsheet assembly. The AI Factory delivered by Ksolves changed both: a governed Apache Iceberg Data Lakehouse on AWS S3 now unifies all seven sources, and an LLM-powered natural language search engine gives every business user conversational access to the full enterprise data estate.
The Smart Quotation Engine provided immediate commercial value, generating margin-aware quotes from unified data and removing the pricing inconsistency that came from assembling proposals manually across disconnected systems.
The open-source, cloud-neutral architecture — built on Apache NiFi, Kafka, Iceberg, and Spark, means the platform is fully extensible. Demand forecasting, lead scoring, predictive pricing, and analytics across HR, supply chain, and finance can all be added on the same governed foundation already in production. For organisations looking to build on this kind of foundation, Ksolves’ Big Data services cover the full stack from ingestion to AI layer.
Ready to Unify Your Enterprise Data and Put Ai-Powered Search in the Hands of Every Business User?














