Project Name
How Ksolves Achieved 90% Faster IoT Data Collection with a Golang SNMP Poller

![]()
When your network monitoring platform needs to poll millions of IoT devices every hour and your legacy system takes the full hour to complete a single pass, you have no margin for growth, no room for higher frequency, and no buffer against the next spike in device volume. For a leading US-based network monitoring provider, this was not a future risk. It was happening in production every day.
The client is a B2B SaaS company specializing in network monitoring and management for enterprise and mid-market customers across the United States. Their platform enables IT and network operations teams to monitor, manage, and report on large-scale device estates spanning routers, switches, servers, and IoT endpoints. With a rapidly expanding customer base and device volumes growing with every new enterprise account, the performance limitations of their legacy Simple Network Management Protocol (SNMP) poller had become a critical operational risk.
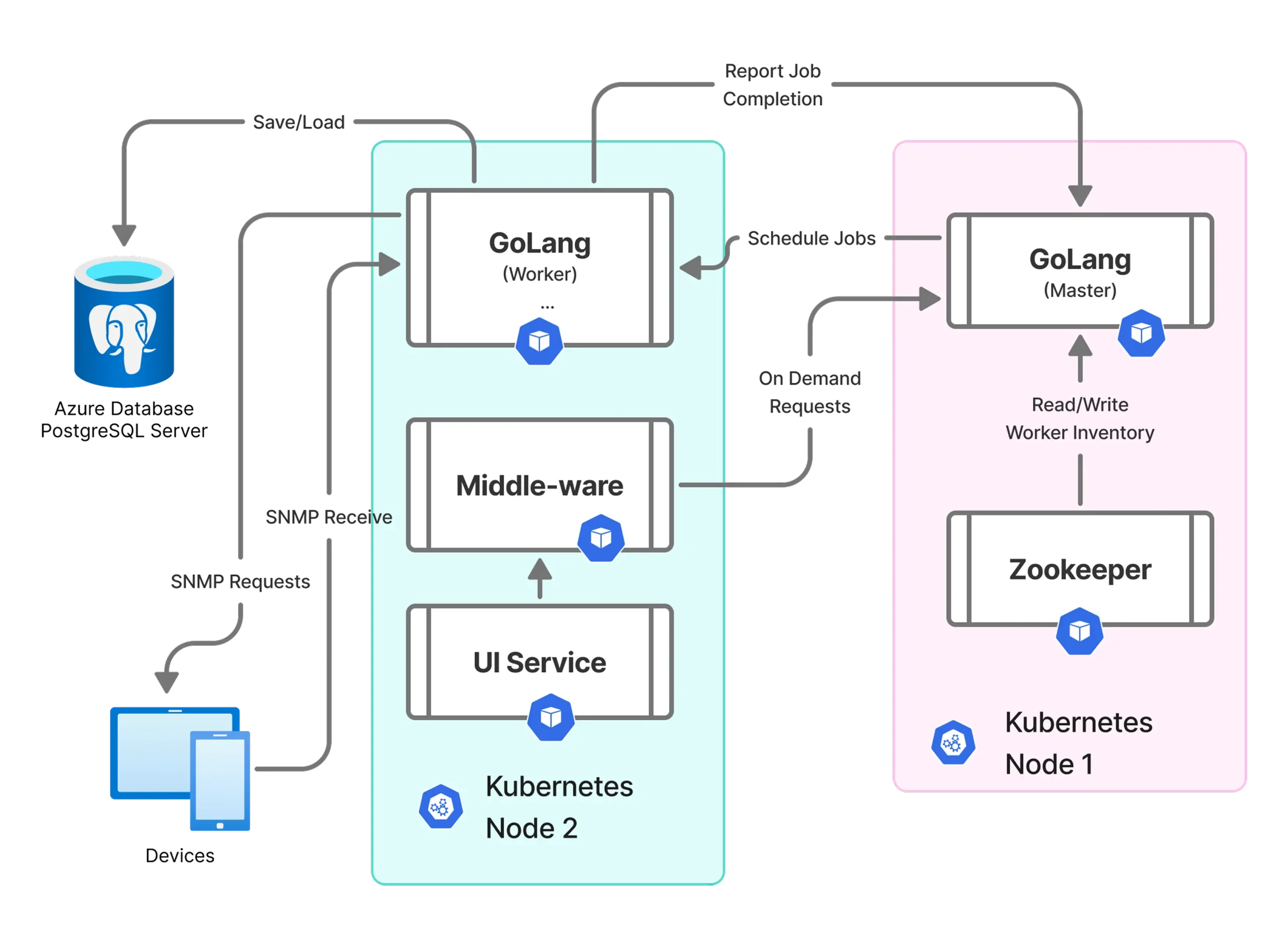
Ksolves rebuilt the SNMP poller from the ground up, replacing a sequential, single-threaded implementation with a goroutine-native, cloud-deployed architecture designed to handle millions of concurrent device polls without overloading the infrastructure beneath it.
The client's legacy SNMP poller presented three compounding operational problems that grew worse with every new device added to the network:
- Scalability Bottlenecks Blocking Growth: The legacy data collector took close to 60 minutes to complete a single collection cycle across the client's device estate. Every new enterprise customer onboarded added more devices and extended that cycle further, creating a direct conflict between customer acquisition and platform performance. At the rate of device growth the client was experiencing, collection cycles would eventually exceed the monitoring window entirely.
- Inability to Increase Collection Frequency: Customer SLAs increasingly required near-real-time device visibility. The legacy system's single-threaded design made sub-hourly collection cycles impossible without triggering system overload or dropped data. The client could not commit to the monitoring frequency their enterprise accounts required without first solving the underlying architecture problem.
- CPU and RAM Saturation Under Load: Concurrent polling attempts caused CPU and RAM to spike unpredictably under load. Resource saturation events resulted in partial collection failures, dropped device data, and inconsistent monitoring outputs. With no headroom in either metric, capacity planning for device volume growth was effectively impossible.
As an AI-first company, Ksolves used AI-assisted concurrency modeling and architecture review to identify optimal goroutine pool configurations before production development began. The re-engineering was executed in four structured phases, each designed to eliminate the previous system's constraints without disrupting live monitoring operations.
- High-Concurrency Design with Goroutines: Ksolves replaced the sequential polling loop with a goroutine-per-device model, enabling hundreds of thousands of concurrent SNMP requests. Golang's lightweight goroutine scheduler manages thread lifecycles with negligible overhead, providing the same concurrency model that powers Google's internal infrastructure at scale. The result was a poller capable of handling millions of devices simultaneously rather than sequentially.
- Resource Governance with Ant, Fiber, and Go Context: Concurrency alone is not enough; uncontrolled goroutine proliferation causes the same resource saturation as a single-threaded bottleneck. Ksolves combined Golang's concurrency primitives with the Ant worker pool library, Fiber's non-blocking HTTP layer, and Go's Context package to enforce timeouts, prevent goroutine leaks, and cap resource consumption. CPU and RAM now stay within defined operational bounds regardless of concurrent device volume.
- Cloud-Native Deployment on Kubernetes: The new SNMP poller was deployed inside a Kubernetes cluster, enabling horizontal scaling, health checking, and zero-downtime rollouts. The architecture integrates natively with TimescaleDB for time-series metrics storage and Apache Cassandra for high-throughput device metadata, providing a unified data layer that scales with device volume independently of the polling engine.
- High Availability with Apache Zookeeper: Distributed coordination via Apache Zookeeper provides leader election and automated failover, ensuring the poller continues operating without interruption during node failure or deployment cycles. The architecture eliminates the single point of failure that made the legacy system vulnerable to any infrastructure disruption.
Technology Stack
| Component | Details |
|---|---|
| Language | Golang (Go) |
| Concurrency | Goroutines, Go Context package |
| Worker Pool | Ant library |
| HTTP Layer | Fiber framework |
| Orchestration | Kubernetes |
| Time-Series Database | TimescaleDB |
| NoSQL Database | Apache Cassandra |
| Distributed Coordination | Apache Zookeeper |
| Protocol | SNMP |
| Deployment Model | Containerized, Kubernetes cluster |
The Golang re-engineering delivered measurable improvements across collection speed, device capacity, resource utilization, and platform scalability:
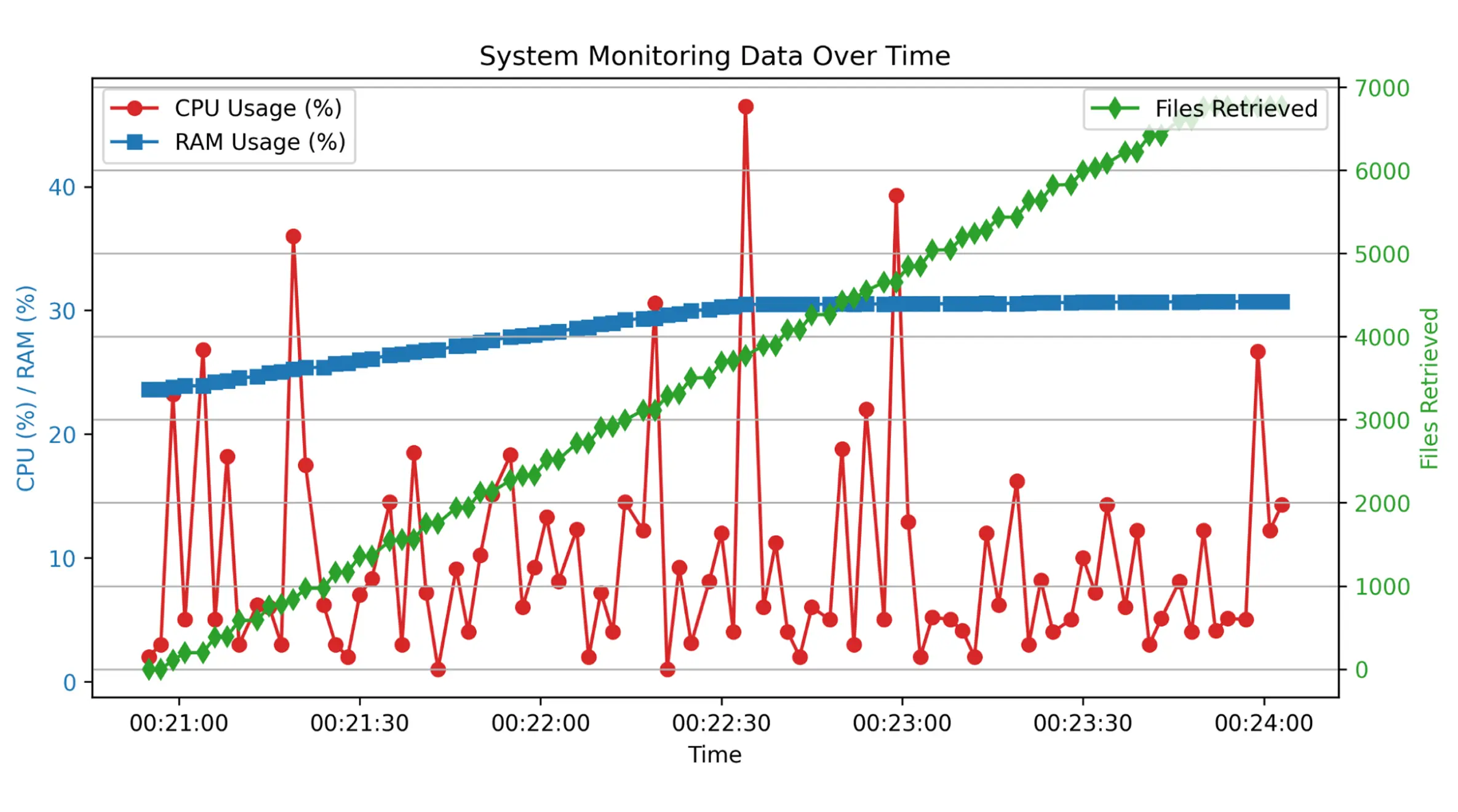
- 90% Faster Collection Cycles: Data collection time dropped from 60 minutes to 3 minutes per cycle, enabling the platform to run 20 monitoring passes per day instead of one. Network operations teams gained near-real-time visibility into device health across their entire estate, supporting SLA commitments that were previously impossible to fulfill.
- 7,000 Devices Collected Per Cycle: The poller now collects data from 7,000 devices within a single 3-minute cycle, matching the client's full active device estate. New enterprise customers can be onboarded and fully monitored on day one, without waiting for collection architecture to catch up.
- CPU Capped at 50% at Peak Load: Even at maximum concurrent polling volume, CPU utilization peaks at 50%, leaving a 50% headroom buffer that supports double the current device volume without infrastructure changes or additional provisioning.
- RAM Stable at 30% Throughout Collection: RAM consumption holds steady at 30% throughout peak collection periods, eliminating the memory saturation events that previously caused partial collection failures and dropped device data.
- Sub-Hourly Monitoring Now Possible: With 3-minute collection cycles available, the client can now commit to near-real-time monitoring SLAs for enterprise accounts, a capability the legacy architecture made structurally impossible regardless of how much infrastructure was added.
“Our legacy poller was our biggest constraint. Every new customer we onboarded made it worse. The Golang rewrite gave us a platform we can actually grow on. We went from one monitoring pass a day to 20, at half the CPU we were burning before.”
— VP of Engineering, US Network Monitoring Platform
By re-engineering the SNMP poller with Golang’s high-concurrency architecture, Ksolves, with its AI-first delivery approach, transformed a 60-minute sequential bottleneck into a 3-minute parallel collection engine capable of handling millions of devices at 50% peak CPU and 30% RAM.
The platform can now fulfill real-time monitoring SLAs that were previously out of reach, onboard new enterprise accounts without performance degradation, and scale device volume without infrastructure rework. As the client’s network monitoring platform expands into new markets and higher device counts, the Kubernetes-native, goroutine-based foundation Ksolves built scales horizontally alongside it.
For network monitoring providers, IoT platforms, and any team managing large-scale device polling at high frequency, explore Ksolves Golang Development Services and find out what a production-grade concurrency architecture looks like for your platform.
Don’t Let Legacy Performance Slow You Down. Modernize Now!