

Top 5 Reasons to Use the Apache Cassandra Database
Apache Cassandra
5 MIN READ
April 10, 2026
![]()

Apache Cassandra has long been the infrastructure backbone behind companies like Apple, Netflix, Walmart, and Huawei. What changed in 2024 was not the workload profile it handles; that has always been large, distributed, and write-intensive. Originally created at Facebook in 2008, Cassandra has become the distributed NoSQL database behind some of the world’s most data-intensive systems, including Apple, Netflix, Walmart, and Huawei. With the release of Apache Cassandra 5.0 in October 2024, the platform took a major step forward, adding native vector search, AI-ready indexing, automated compaction, and stronger security. It now powers over 30,000 organizations worldwide.
Ksolves enhances this further with its AI-enabled approach, using intelligent tools to accelerate implementation, optimize performance, and reduce deployment risks. With AI-driven expertise, Ksolves helps organizations unlock the full potential of Cassandra 5.0 faster and more efficiently.
In this blog, we are discussing the five reasons that show why Cassandra 5.0 deserves serious consideration for your next database decision.
5 Reasons to Build on Apache Cassandra 5.0 in 2026
Here are key reasons to choose Apache Cassandra 5.0 in 2026:
- Performance and Scalability That Grows With Your Data
Cassandra handles speed through two architectural decisions working in tandem. A consistent hashing algorithm routes every write directly to the responsible node, cutting out the coordination overhead that master-node systems carry. Every node in the cluster performs the same role, which means adding nodes scales both read and write throughput linearly, no downtime, no re-architecture required.
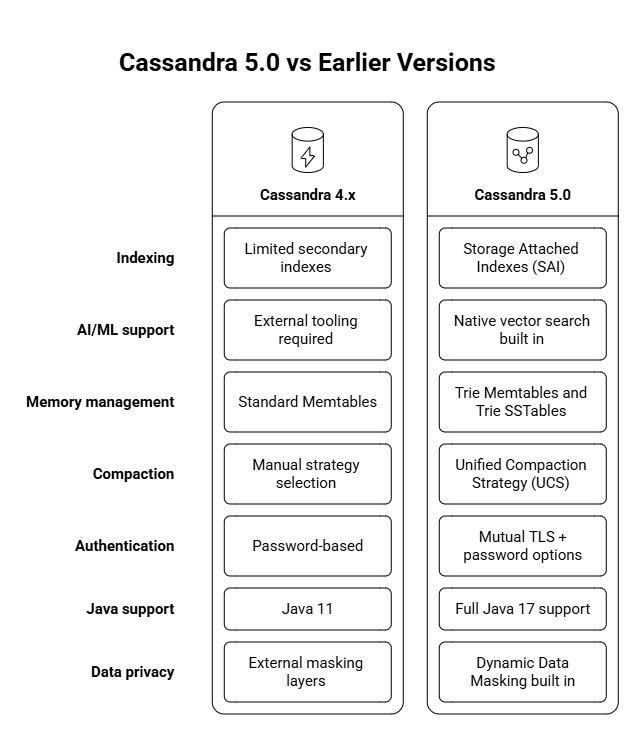
For write-intensive workloads like IoT telemetry, event streams, or financial transaction logs, Cassandra’s LSM tree indexing outperforms traditional B-tree systems by batching writes into sequential disk operations. Cassandra 5.0 pushes this further with Trie Memtables and Trie SSTables, which improve both in-memory and on-disk performance without requiring any changes to existing data models. Teams upgrading from Cassandra 4.x get measurable speed gains simply by moving to the new version.
Cluster membership is handled automatically through the gossip protocol. New nodes announce themselves, exchange metadata with peers, and integrate without manual intervention. Scaling is an operational step, not an engineering effort.
- High Availability With No Single Point of Failure
There is no master node in a Cassandra cluster. Every node carries equal responsibility. If multiple nodes fail at the same time, the cluster continues serving requests based on the configured replication factor and consistency level. This is normal operation, not a fallback state. Rolling upgrades follow the same pattern. Updates are applied node by node while the rest of the cluster stays live. No maintenance windows. No service interruptions for minor or patch releases.
Multi-data center replication is native to Cassandra’s architecture. Data can be distributed across geographic regions for regulatory compliance, disaster recovery, or low-latency access from different parts of the world. If an entire data center goes offline, traffic routes to surviving replicas automatically. Cassandra 5.0 strengthened this with Mutual TLS Authentication, replacing password-based access with certificate-based auth for teams operating in regulated environments.
- Tunable Consistency for Every Workload
Cassandra offers per-operation consistency, allowing flexibility across workloads. High-volume ingestion can use ONE for faster writes, while critical queries can use QUORUM to ensure accuracy. This enables a single cluster to support diverse applications.
Compaction is equally adaptable. Write-heavy systems can delay compaction to maintain throughput, while read-heavy systems can optimize for faster queries. With Cassandra 5.0’s Unified Compaction Strategy (UCS), this tuning is automated, reducing manual effort.
In multi-data center environments, each center can apply its own consistency and compaction settings, allowing write and read workloads to efficiently share the same data.
- Native Integration With AI and the Modern Data Stack
Cassandra is built to work as part of a larger data ecosystem, not in isolation. It integrates seamlessly with Apache Spark for analytics and ML, Apache Kafka for real-time data ingestion, and Apache Solr for full-text search.
With Cassandra 5.0, capabilities expanded further through native vector search using Storage Attached Indexes (SAI). This removes the need for a separate vector database, simplifying architecture and eliminating synchronization overhead.
SAI also improves query flexibility. Earlier versions required heavy denormalization for non-primary key queries, but SAI enables efficient querying at scale, making Cassandra more adaptable to changing application needs.
- A Proven Track Record Across Industries
Cassandra’s production record extends well beyond technology companies. Financial institutions use it for high-frequency transaction storage and fraud detection event streams. Healthcare companies store time-series sensor data and patient monitoring logs. E-commerce platforms use it for product catalogs and user sessions that must hold up under unpredictable traffic spikes. Web analytics firms store clickstream data in Cassandra because the write volume and access patterns are a natural fit for its architecture.
The 2025 release cycle delivered 26 releases across five active branches, backed by over 40 unique contributors. Cassandra’s development pace and adoption at the scale of Apple, Netflix, and Walmart signal long-term project health for teams making infrastructure decisions with a multi-year horizon.
Cassandra 5.0 also added Dynamic Data Masking, which enforces column-level masking at query time based on user permissions. Healthcare and financial teams can meet data privacy requirements directly at the database layer, without building masking logic into the application.
Still comparing options? Our guide on Apache Cassandra vs other NoSQL databases covers the key differences in scalability, consistency model, and query flexibility.
Why Choose Ksolves for AI-Enabled Cassandra Implementations?
Ksolves is backed by AI-enabled Cassandra consultants that use AI tools as a standard part of every engagement, like schema design review, optimization, cluster configuration, and documentation, all run through AI-assisted workflows. For your project, this compresses the typical implementation timeline by roughly 50% and reduces the configuration errors that cause post-production incidents.
If your team is evaluating Cassandra 5.0 for a new build or planning a migration from an older version, Ksolves AI-enabled Cassandra experts have the hands-on experience to get your cluster production-ready without the months of trial and error that complex distributed databases typically require. Contact Ksolves to discuss your Cassandra requirements.
Conclusion
Cassandra 5.0 removes several categories of complexity that teams previously solved with external tooling or manual configuration, native vector search, automated compaction, and built-in data masking being the clearest examples. The core strengths remain unchanged: linear scalability, masterless fault tolerance, and deep Apache ecosystem integration. For teams running data-intensive applications at any meaningful scale, this release makes Cassandra a stronger candidate than it has ever been.
If you are planning a Cassandra 5.0 upgrade, Ksolves AI-enabled experts can help you modernize your architecture, optimize performance, and ensure a smooth migration. With an AI-first approach, we reduce risks, improve efficiency, and accelerate delivery. Contact Ksolves to get started with an expert-led Cassandra transformation.
![]()


Apache Flink is the backbone of real-time data pipelines across financial services, e-commerce, IoT, and logistics. But as the state […]













AUTHOR
Apache Cassandra
Anil Kushwaha, Technology Head at Ksolves, is an expert in Big Data. With over 11 years at Ksolves, he has been pivotal in driving innovative, high-volume data solutions with technologies like Nifi, Cassandra, Spark, Hadoop, etc. Passionate about advancing tech, he ensures smooth data warehousing for client success through tailored, cutting-edge strategies.
Share with