Project Name
Real-Time PostgreSQL CDC Pipeline with Debezium & Apache Kafka
![]()
Our client is a B2B fintech lending firm headquartered in North America, serving over 200 enterprise clients across the United States and Canada. With a workforce of approximately 350 employees and a dedicated analytics division of 14 data analysts and engineers, the firm sits firmly in the mid-market segment, processing upwards of 600,000 financial transactions per day through a production PostgreSQL database shared with live lending operations.
The analytics team depended on this database for real-time risk dashboards, loan decisioning, and regulatory reporting, but direct production access was off the table due to the risk of query-induced latency spikes on a mission-critical lending system. Batch ETL refreshes were creating data lags of up to 6 hours, compressing decision windows, and exposing the business to risk on time-sensitive credit calls. Commercial replication tools such as AWS DMS and GoldenGate were evaluated, but were estimated at $120,000 per year, far beyond the client’s infrastructure budget. Ksolves designed and implemented a real-time CDC pipeline using Debezium and Apache Kafka on open-source tooling, delivering sub-second replication to three synchronized analytics databases with zero impact on the production system.
- Stale Data Undermining Lending Decisions: Credit risk models and loan performance reports run on batch data refreshed every 6 hours. During periods of market movement, analysts were forced to delay decisions until the next cycle, creating measurable credit risk exposure and slowing the firm's underwriting velocity.
- Production Database at Risk from Analytics Queries: Direct analytics access to the production PostgreSQL database risked processing delays on live loan applications during peak periods. The team needed full isolation of analytics workloads from the production system without exception.
- Cost-Prohibitive Commercial Replication Tools: Enterprise CDC platforms were quoted at $90,000 to $140,000 annually. Supporting three destination databases without per-connector fees made open-source the only viable option, but the team lacked the expertise to implement it at scale.
- No Visibility into Pipeline Health: When batch ETL jobs failed silently, the analytics team found out through stale dashboards, sometimes hours later. Any replacement architecture needed end-to-end observability and proactive alerting built in from day one.
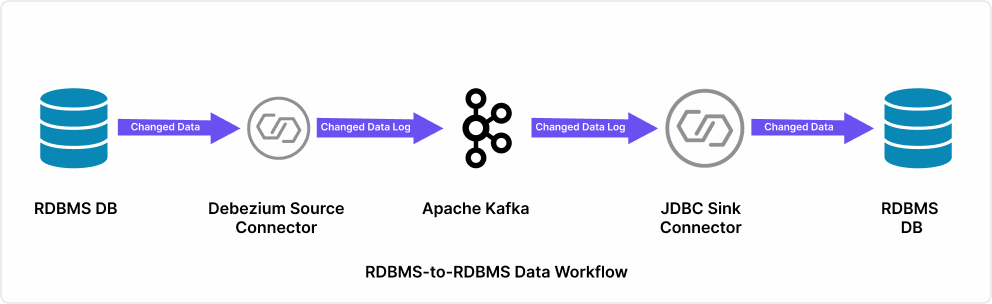
Ksolves designed and delivered a full CDC replication architecture using Debezium, Apache Kafka, and the JDBC Sink Connector, streaming every database change to three synchronized analytics databases in near real-time.
- Log-Based CDC via Debezium and PostgreSQL WAL: Debezium was configured as a Kafka source connector, reading from PostgreSQL's Write-Ahead Log rather than querying live tables, eliminating all replication-related load on the production lending system. Every data change across 47 monitored tables was captured at the transaction level and published to dedicated Kafka topics.
- Three-Node Apache Kafka Cluster: A three-node Kafka broker cluster was deployed to handle 600,000 daily transactions with built-in fault tolerance. Topics mapped directly to the source schema, allowing the pipeline to scale horizontally as loan volumes grew without re-engineering the core architecture.
- JDBC Sink Connector for Multi-Destination Replication: The Kafka Connect JDBC Sink Connector wrote CDC events to all three destination analytics databases simultaneously, replacing the serial 6-hour batch process with a parallel, event-driven model that kept every destination continuously in sync.
- Prometheus, Grafana, and Kafka UI for Full Observability: Prometheus and Grafana were deployed to monitor consumer lag, connector status, throughput, and end-to-end latency across all topics. Kafka UI provided the operations team with a browser-based interface for day-to-day cluster management, replacing silent ETL failures with real-time alerts.
Technology Stack
| Layer | Technology |
|---|---|
| Change Data Capture | Debezium 2.4 (PostgreSQL Connector) |
| Message Streaming Platform | Apache Kafka 3.6 (3-Node Cluster) |
| Kafka Sink Connector | JDBC Sink Connector 10.7 |
| Source Database | PostgreSQL 15 (WAL / Logical Replication) |
| Destination Databases | 3 PostgreSQL Analytics Instances |
| Pipeline Monitoring | Prometheus 2.48 + Grafana 10.2 |
| Cluster Management UI | Kafka UI 0.7 (Open-Source) |
| Legacy Approach (Replaced) | Batch ETL (6-Hour Scheduled Jobs) |
- Sub-Second Replication Latency: End-to-end CDC latency reduced to under 800 milliseconds across all three destination databases, replacing the previous 6-hour batch lag with data accurate to within one second of production.
- Zero Production Performance Impact: Debezium's WAL-based capture introduced no measurable query load on the source PostgreSQL database, even during peak lending periods, processing over 40,000 transactions per hour.
- Three Destinations Synchronized Simultaneously: All 47 monitored tables now replicate in parallel to three analytics databases through the Kafka cluster, replacing the previous serial batch model entirely.
- 83% Cost Saving vs Commercial CDC Tools: The open-source implementation costs approximately $20,000 per year in infrastructure, compared to the $120,000 annual estimate for commercial alternatives, saving the firm around $100,000 per year.
- Lending Decisions Backed by Live Data: Credit risk models, loan dashboards, and regulatory reports now run on data under one second old, eliminating the 6-hour blind spot that had been compressing the firm's underwriting decision windows.
- Proactive Alerting Across All 47 Tables: Automated alerts now trigger within 60 seconds of any pipeline anomaly, replacing the silent failure model that had previously left stale data undetected for hours.
“We had spent months evaluating CDC tooling and kept hitting the same wall: commercial platforms were priced for enterprises three times our size, and the 6-hour batch ETL cycle we were running was creating data lags our lending analysts simply could not work around. Ksolves implemented the Debezium + Kafka pipeline in under six weeks, and we have been running sub-second replication to three analytics databases ever since. Our risk team stopped asking about data freshness. That tells you everything.”
-Head of Data Engineering, Fintech Lending Firm (Anonymized per NDA)
Before Ksolves, this fintech lending firm’s analytics team ran on batch data 6 hours behind production, compressing underwriting decisions and creating real credit risk exposure during fast-moving market conditions. Today, their Debezium + Kafka pipeline streams every change from the production PostgreSQL database to three synchronized analytics destinations in under one second, with zero production impact and an 83% reduction in replication cost.
As an AI-first company, Ksolves brings deep expertise across CDC pipeline design, real-time streaming infrastructure, and full-stack observability. If your organization is running batch ETL on PostgreSQL, MySQL, or SQL Server and needs a real-time replication layer for analytics or ML workloads, our experts will build the right architecture for your data volume and latency requirements. Get started with Ksolves Kafka Consulting Service today.
Ready to Replace Batch ETL with Real-Time CDC?