

Project Name
How Ksolves Migrated a Healthcare Provider from Apache Kafka to Redpanda with Zero Downtime and 38% Lower Streaming Costs with AI

![]()
A US-based healthcare technology company had a Kafka problem that had nothing to do with Kafka itself. The platform was working. The data was flowing. But their managed Kafka deployment (47 topics, 12 consumer groups, 3.2 TB of clinical and operational data moving through it every day) was eating 14 hours of engineering time per week just to keep running. Cluster maintenance, version upgrades, consumer group monitoring, incident response. All of it landed on a lean engineering team that had more valuable things to do.
The client is a mid-size B2B healthcare technology organisation with over 200 employees, providing real-time data processing infrastructure for clinical and administrative workflows across a network of healthcare facilities. Real-time data is not optional in their environment. A gap in the pipeline is a gap in operations. So when they decided to migrate from managed Kafka to Redpanda, a lighter Kafka-compatible streaming platform that costs significantly less to run, the non-negotiable condition was simple: nothing stops, and nothing gets lost.
Ksolves took that on. What usually takes 11 days of manual planning to scope, Ksolves completed in 6 using AI-assisted Kafka topology analysis. The full migration of all 47 topics and 12 consumer groups was done in 3 weeks, with zero service interruptions and zero data loss.
The decision to replace managed Kafka with Redpanda did not happen overnight. Three specific problems made it unavoidable.
- Kafka Management Overhead Eating Into Engineering Capacity: Managed Kafka running at this scale requires constant attention. Version management, partition rebalancing, consumer lag monitoring, broker health checks. None of it is automatable without significant tooling investment. The team was spending 14 hours per week on cluster operations that had nothing to do with building healthcare data products. That number was going up, not down, as data volumes grew. The infrastructure was consuming more than it was enabling.
- Zero-Downtime Migration With Exactly-Once Delivery Was Non-Negotiable: Kafka-to-Redpanda migration is not a simple swap. Every topic offset, every consumer group checkpoint, every in-flight message had to be accounted for. Healthcare data records cannot be duplicated or dropped. A missing lab result or a duplicated transaction is not a data quality issue, it is a clinical and compliance risk. A hard cutover was out of the question. The migration had to run live, in phases, with continuous validation at every step across 3.2 TB of daily throughput.
- Connector and Consumer Compatibility Across 12 Existing Applications: The client's data ecosystem included 12 consumer applications and several Kafka Connect connectors that processed clinical and operational data downstream. Each one had to keep working without code changes during and after the migration. Any API break, schema mismatch, or offset discontinuity would cascade into failures across workflows that run healthcare operations. Compatibility was not something to test at the end. It had to be proven upfront, before a single production topic moved.
The migration strategy came down to one rule: validate before you move, not after. Before configuring a single connector, Ksolves used AI tools to map the client's complete Kafka topology: all 47 topics, 12 consumer groups, connector configurations, offset states, and consumer dependencies. This kind of discovery work typically takes 11 days when done manually. AI-assisted analysis completed it in 6, producing a sequenced migration plan with compatibility risks identified and addressed before the migration began. The 3-week execution ran against that plan without a single rollback.
- Phased Migration to Reduce Kafka Costs Immediately: Rather than migrating all topics at once, Ksolves built a phased sequence that moved the highest-cost, lowest-risk topics to Redpanda first. This cut managed Kafka infrastructure costs from week one, progressively reducing the managed cluster footprint while all 12 consumer groups stayed operational throughout. Redpanda cluster sizing was matched to the client's actual throughput needs, not the legacy cluster's over-provisioned capacity.
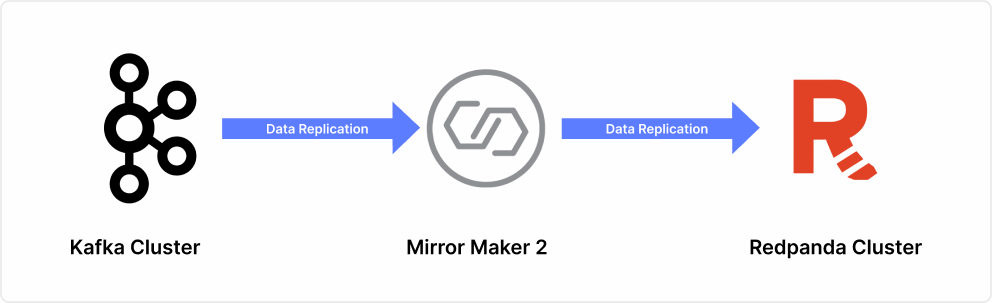
- MirrorMaker 2.0 Live Replication: As Apache Kafka migration specialists, Ksolves deployed MirrorMaker 2.0 as the live replication engine for the entire migration window. Three connectors ran in parallel using the Kafka Connect framework: the MirrorSourceConnector handled offset translation and exactly-once delivery semantics across all 47 topics; the MirrorCheckpointConnector preserved consumer group state and checkpoint continuity across all 12 consumer groups; the MirrorHeartbeatConnector monitored replication health and measured latency continuously. Kafka and Redpanda ran side by side until every topic was validated and every consumer was confirmed compatible on the new platform.
- Compatibility Testing Before Any Production Cutover: Before any live topic was cut over to Redpanda 25.2.7, Ksolves ran full API and schema compatibility tests against every connector and consumer application. Topic configurations, consumer group offsets, and Kafka API behaviour were systematically verified against Redpanda's Kafka-compatible interface. All 12 consumer applications passed without a single code change, removing the re-engineering risk that had been the team's biggest concern from day one.
- Real-Time Monitoring With Prometheus and Grafana: Prometheus 3.11.0 scraped connector metrics, replication lag, and topic offset alignment throughout the migration. Grafana 13.0.1 dashboards gave the team live visibility into migration health at every stage. A corresponding Redpanda topic was created and validated before each Kafka topic was replicated. Data consistency was checked by cross-referencing record counts and offsets in real time, not as a one-time post-migration verification, but as a continuous check running for the entire 3 weeks.
- Automated Error Recovery Built In: Automatic failover, structured error logging, and failed-message retry were built into the migration pipeline from the start. Any transient network interruption or connector failure triggered automatic recovery. The team did not need to intervene manually for transient issues, and no data was lost during the client's concurrent infrastructure maintenance windows.
Technology Stack:
| Component | Version | Role |
|---|---|---|
| Apache Kafka | 3.9.2 | Source platform; managed deployment being migrated from |
| Redpanda | 25.2.7 | Target platform; Kafka API-compatible, self-managed, no JVM overhead |
| MirrorMaker 2.0 | Kafka Connect | Live replication engine between Kafka and Redpanda throughout migration |
| MirrorSourceConnector | MM2 component | Offset translation and exactly-once delivery for all 47 topics |
| MirrorCheckpointConnector | MM2 component | Consumer group state and checkpoint management across 12 consumer groups |
| MirrorHeartbeatConnector | MM2 component | Continuous replication health monitoring and latency measurement |
| Prometheus | 3.11.0 | Real-time connector status, replication lag, and offset consistency metrics |
| Grafana | 13.0.1 | Live migration health dashboards and post-migration operations monitoring |
- Zero Downtime Across 3 Weeks of Migration: All 47 topics and 12 consumer groups were moved to Redpanda without a single service interruption. Clinical and operational data flows stayed continuous through every phase of the migration. No cutover window. No maintenance downtime. No gap in the pipeline.
- 100% Data Consistency Confirmed: Prometheus 3.11.0 monitoring and record-level cross-validation confirmed zero message duplication, zero message loss, and complete offset alignment between Kafka and Redpanda across all 47 topics. Exactly-once delivery semantics held for the full 3.2 TB daily throughput from start to finish.
- 38% Reduction in Streaming Infrastructure Cost: Moving from managed Kafka to self-managed Redpanda cut monthly streaming infrastructure spend by 38%, saving an estimated $96,000 per year at the client's data volume. Managed service fees, over-provisioned cluster costs, and per-partition charges were all eliminated.
- 12 Consumer Applications Running Without Code Changes: Every Kafka Connect connector and consumer application continued operating against Redpanda 25.2.7 without modification. Full API compatibility was confirmed across all 12 applications before any production cutover.
- 14 Engineering Hours Per Week Recovered: Post-migration, the team stopped spending 14 hours per week on Kafka cluster maintenance. That time is now going toward healthcare data product development instead of infrastructure management.
- AI-Assisted Planning Cut Scoping Time Nearly in Half: Ksolves' AI-assisted topology analysis mapped all 47 topics, consumer groups, and connector dependencies in 6 days. A manual approach would have taken 11. The earlier start and validated plan meant the 3-week migration ran without rework.
“Migrating away from managed Kafka without disrupting our real-time clinical data flows was not something we were willing to attempt without the right partner. Ksolves’ MirrorMaker 2.0 approach gave us exactly the controlled, zero-downtime migration we needed. The cost reduction showed up on our infrastructure bill from the first month, and our engineering team has not looked back.”
— Head of Data Engineering, US Healthcare Technology Organisation (Anonymised per NDA)
From 14 engineering hours per week consumed by managed Kafka maintenance, to a self-managed Redpanda cluster running 38% cheaper with zero operational disruption and full data continuity. That is what replacing managed Kafka with Redpanda looks like when the migration is planned and executed correctly. With 12+ years of experience, a team of experienced Apache Kafka engineers and migration specialists, and a 90% client retention rate, Ksolves brings the same discipline to every streaming infrastructure engagement. Whether you are planning a Kafka-to-Redpanda migration, reducing managed Kafka costs, or need ongoing Apache Kafka support services to assess your migration risk and timeline, Ksolves can scope the right path for your environment.
Get a Free Kafka Migration Assessment Today!














