

Trino vs. Presto: History, Differences, and Which to Use in 2026
Big Data
5 MIN READ
May 12, 2026
![]()

When data engineers debate Trino vs Presto in 2026, the confusion is entirely understandable. Both tools share the same original codebase, both promise fast distributed SQL engine capabilities at scale, and both are widely referenced in big data architecture conversations. Yet they have followed fundamentally different paths since 2019 and now serve different audiences with different priorities. Understanding history and what it means for your production stack today is the key to making the right choice for your organisation.
This guide walks through the origins of both engines, explains the technical fork that created Trino, compares their key differences in a structured way, and closes with a practical decision framework for teams evaluating both options.
A Shared Origin: How Presto Was Built at Meta
Presto was created at Meta (then Facebook) in 2012 to solve a very specific problem. Meta’s data teams needed a way to run interactive SQL queries across massive HDFS datasets without waiting hours for MapReduce jobs to complete. The engineering team built a distributed SQL engine that could deliver results in seconds. By 2013, Meta had open-sourced the project under the Apache License 2.0.
Over the following years, Presto became one of the most widely adopted SQL layers for big data infrastructure globally. Companies including Airbnb, Uber, Netflix, LinkedIn, and Twitter built significant analytics capabilities on top of it. The project’s community grew steadily, and multiple vendors began offering Presto-based products and managed distributions.
This growth, however, also introduced tension. As Presto’s usage expanded far beyond Meta’s own infrastructure, questions around governance, release quality, and community-driven development priorities became harder to resolve within a project still effectively controlled by a single company.
The Fork: Why PrestoSQL Became Trino
In 2018, four of the original Presto engineers at Meta, Martin Traverso, Dain Sundstrom, David Phillips, and Eric Hwang, left the company and continued developing Presto independently under the name PrestoSQL. Their objective was to maintain a community-driven open-source query engine focused on engineering quality, open governance, and the needs of a broader user base rather than a single corporate sponsor’s internal requirements.
The PrestoSQL vs Presto fork diverged meaningfully from Meta’s version over the following two years. In December 2020, the project was officially renamed Trino to avoid ongoing confusion with PrestoDB, the version that Meta continued to develop alongside its commercial partner Ahana. The rename was accompanied by a move to the Trino Software Foundation, giving the project clear independent governance.
The result today is two active but distinct projects. Trino is maintained by the original creators and a broad open-source community through the Trino Software Foundation. PrestoDB, often still referred to simply as Presto, is maintained primarily by Meta and Ahana and remains production-hardened for Meta-scale infrastructure.
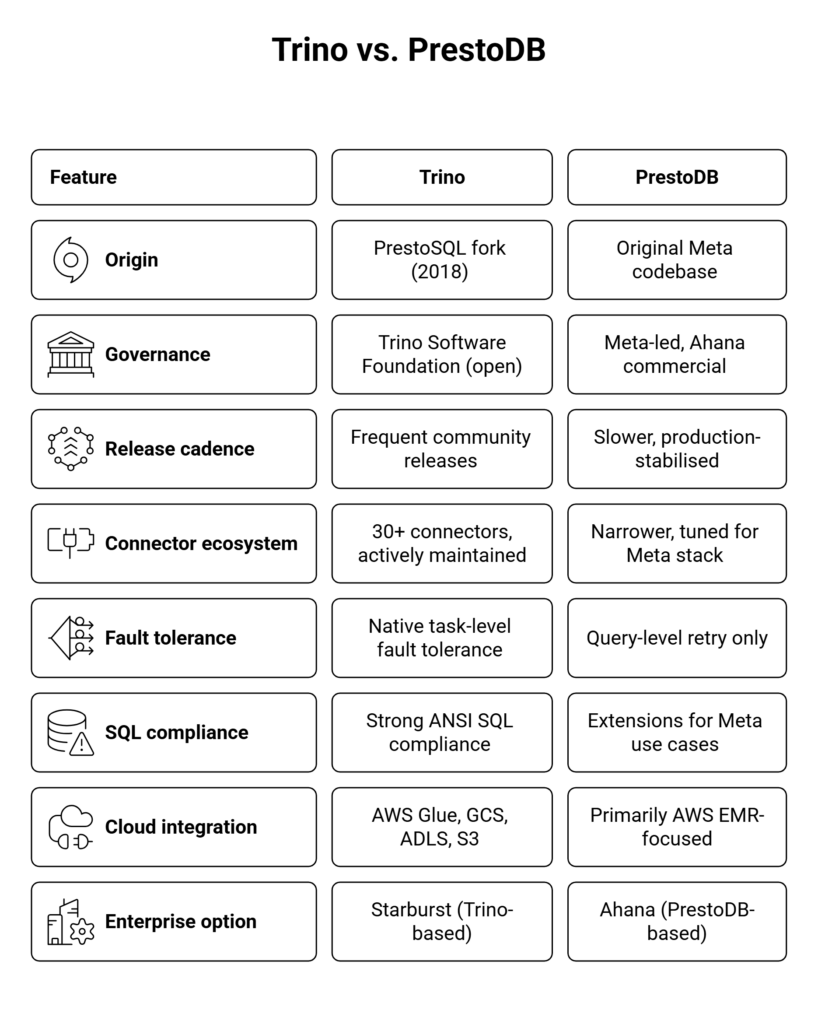
Trino vs. Presto: Key Technical Differences
Both engines execute distributed SQL queries using a coordinator-worker architecture where a single coordinator node parses queries, plans execution, and distributes work to multiple worker nodes. Beyond that shared foundation, the two projects have diverged significantly across several important dimensions.
Performance: Where Each Engine Has an Advantage
In standard ad-hoc SQL analytics benchmarks, Trino and PrestoDB perform comparably. Both engines use in-memory, pipelined execution and avoid writing intermediate results to disk for most operations. Where Trino performance diverges in practice is in fault tolerance, large-join spill-to-disk behaviour, and workload-specific connector optimisations.
Trino’s native task-level fault tolerance, progressively rolled out since version 376, allows individual tasks within a query to recover from worker node failures without restarting the entire query. This is a meaningful advantage for long-running analytical workloads running on spot or preemptible cloud instances, where node interruptions are routine. PrestoDB’s fault tolerance model operates at the query level, meaning a single node failure typically requires a complete query retry from the beginning.
For short, sub-second ad-hoc queries on well-provisioned infrastructure, the fault tolerance difference is less relevant and the raw performance of both engines is effectively equivalent.
For teams running Trino or Presto as a SQL layer over HDFS-based infrastructure, understanding how these engines interact with the broader Apache Hadoop data management architecture is essential for building a coherent and maintainable data platform.
Connector Support and Ecosystem Integration
Trino’s most practical advantage in 2026 is the breadth and active maintenance of its connector ecosystem. Trino ships with connectors for Hive Metastore, Delta Lake, Apache Iceberg, Apache Hudi, PostgreSQL, MySQL, Elasticsearch, Apache Kafka, Cassandra, MongoDB, Redis, and more than 30 other data sources. The open governance model means community connector contributions reach production significantly faster than in a single-sponsor project.
PrestoDB has a more curated set of connectors, optimised for the infrastructure patterns used internally at Meta. For teams outside Meta’s specific data stack, this frequently means additional development effort to connect Presto to the data sources their organisation actually uses in production.
Apache Iceberg support is a particularly important dimension in 2026. Trino has invested heavily in native Iceberg support, including schema evolution, time travel queries, and partition pruning. PrestoDB’s Iceberg support exists but has historically lagged behind Trino’s in feature completeness for open lakehouse use cases.
Teams evaluating Trino as a query layer over HBase or building architectures that combine batch and streaming sources should also review big data integration patterns with Apache Spark and HBase to understand how these components compose in a modern lakehouse stack.
Which Should You Use in 2026?
The right choice depends on your organisation’s infrastructure, existing expertise, and long-term platform direction.
Choose Trino if:
- You need a wide connector ecosystem that is actively maintained by the open-source community
- Your data lake uses Apache Iceberg, Delta Lake, or Apache Hudi as a table format
- Your storage runs on cloud object stores such as S3, Google Cloud Storage, or Azure ADLS
- You run long-running analytical queries on spot or preemptible infrastructure, where fault tolerance matters
- You want the fastest release cadence and broadest community contribution in an open-source query engine
- You need Trino vs Starburst enterprise options with commercial support and additional governance features
Choose PrestoDB if:
- Your organisation already runs a Meta-influenced data stack and has internal Presto engineering expertise
- You need commercial support through Ahana with SLA guarantees backed by a vendor
- Your workloads are primarily short, ad-hoc queries on well-provisioned, stable on-premises infrastructure
- Platform stability and minimising change risk outweigh the need for new connector features
For most enterprise teams building or modernising a data platform in 2026, Trino is the stronger default choice. Its open governance, connector breadth, fault-tolerant execution model, cloud-native design, and active community cover a wider range of production use cases. PrestoDB remains a legitimate option for teams with established investment in the Meta-originated ecosystem or a specific need for Ahana’s support structure.
How Ksolves Helps You Implement Trino and Presto
Selecting between Trino and PrestoDB is the beginning of the decision, not the end. Production deployment, cluster sizing, security hardening with access controls and audit logging, performance tuning for your specific query patterns, and integration with your existing Hadoop SQL layer, warehouse, and ingestion infrastructure all require hands-on expertise that goes well beyond reading documentation.
Ksolves delivers end-to-end big data query tool consulting services covering Trino and PrestoDB implementation, cluster architecture design, connector configuration and optimisation, Kerberos-based security, and integration with Apache Hadoop, Apache Spark, Apache Kafka, HBase, and cloud-native platforms including AWS EMR, Azure HDInsight, and Google Cloud Dataproc. With over 12 years of production big data experience and an AI-first delivery model powered by Claude Code and Cursor, Ksolves accelerates your distributed SQL deployment while ensuring it is built for scale, security, and long-term maintainability.
Staying current with the evolving landscape of top big data tools and platforms in 2026 is another dimension Ksolves covers as part of every long-term advisory engagement.
Contact Ksolves today to speak with a big data expert about Trino, PrestoDB, or your broader data platform strategy.
Conclusion
Trino vs Presto is ultimately a question of governance, ecosystem breadth, and long-term platform fit. Both engines trace their origins to pioneering work done at Meta more than a decade ago. In 2026, they serve different audiences. Trino, governed openly by the Trino Software Foundation, offers the wider connector ecosystem, stronger cloud-native integration, native task-level fault tolerance, and the fastest development pace of any community-driven distributed SQL engine. PrestoDB remains a production-hardened option for teams closely aligned with Meta’s infrastructure patterns or with a specific need for Ahana’s commercial support.
For most new deployments, Trino is the right default. The more important question, however, is not which engine you choose but whether it is implemented correctly, tuned for your workloads, and integrated securely with the rest of your data platform. That is precisely where an experienced big data consulting partner adds the most value, and it is exactly what Ksolves is built to deliver.
![]()















AUTHOR
Big Data
Anil Kushwaha, Technology Head at Ksolves, is an expert in Big Data. With over 11 years at Ksolves, he has been pivotal in driving innovative, high-volume data solutions with technologies like Nifi, Cassandra, Spark, Hadoop, etc. Passionate about advancing tech, he ensures smooth data warehousing for client success through tailored, cutting-edge strategies.
Share with