

Redis Open Source vs Redis Enterprise: Key Differences Explained
Big Data
5 MIN READ
May 27, 2026
![]()

Redis is the backbone of real-time applications, powering caching, session stores, leaderboards, queues, and analytics in thousands of systems. As usage grows from simple caches to large-scale, mission-critical, or geo-distributed deployments, teams face a key choice: stick with Redis Open Source or move to Redis Enterprise for enterprise features, global scale, and vendor support.
In this blog, we discuss the key differences between Redis OSS and Redis Enterprise that help you decide which Redis solution fits your needs.
What is Redis Open Source?
Redis Open Source (Redis OSS) is the community distribution of Redis, a blazing-fast, in-memory data structure server. Starting with Redis 8, Redis Stack packages the core server with community modules (e.g., RediSearch, RedisJSON, RedisTimeSeries, RedisBloom) that extend functionality such as full-text search, JSON documents, time-series, and probabilistic data structures. Redis OSS is suitable for caching, simple primary data stores, and smaller-scale real-time workloads.
What is Redis Enterprise?
Redis Enterprise is Redis Ltd.’s (Redis Labs’) commercial offering available as self-managed software, Kubernetes operator, or managed cloud service. It preserves Redis APIs and modules while adding enterprise capabilities: a shared-nothing clustering architecture for linear scale, enterprise high availability and fast failover, Active-Active geo-distribution using CRDTs, DRAM+Flash auto-tiering (previously “Redis on Flash”) for lower storage cost at scale, and 24/7 support and SLAs. These capabilities target large datasets, global applications, and teams that need predictable performance and operational simplicity.
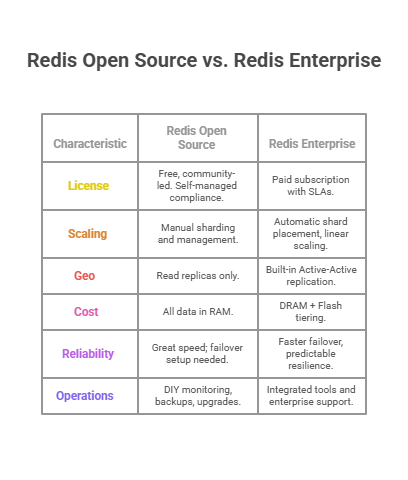
Key Difference between Redis Open Source and Redis Enterprises
Here, we are sharing the key differences between Redis Open Source and Redis Enterprise on different factors.
-
Architecture & Scaling
Redis Open Source:
You can scale the open-source version by running Redis Cluster (which shards data across nodes) or by deploying several standalone instances. Both approaches work well, but they do require engineering effort. Teams must manage key-to-slot mapping, handle cross-slot commands, and build or maintain operational tooling to rebalance data as the cluster grows.
Redis Enterprise:
Enterprise uses a shared-nothing cluster design that automatically handles shard placement and rebalancing. This makes it easier to add nodes for both throughput and capacity without downtime. For teams that need to scale quickly or frequently, the operational burden is far lower than with a self-managed open-source cluster.
-
High Availability & Failover
Redis Open Source:
A common HA setup is one primary node with two replicas, giving three copies to prevent split-brain scenarios. Failover works reliably, but you must configure and monitor it carefully, and recovery time depends on how fast your infrastructure detects and promotes a replica.
Redis Enterprise:
The commercial edition includes built-in enterprise HA. It detects failures quickly and typically recovers in a few seconds. Thanks to its cluster-level quorum mechanism, it can maintain strong availability with just two replicas instead of three, which reduces memory costs while still meeting strict uptime requirements.
-
Geo-Distribution (Active-Active)
Redis Open Source:
Out of the box, open-source Redis cannot accept writes in multiple regions at once. You can create custom replication or application-level conflict handling, but it’s complex and often brittle.
Redis Enterprise:
Enterprise offers true Active-Active replication based on conflict-free replicated data types (CRDTs). Multiple regions can accept writes simultaneously, and the system automatically resolves conflicts. Applications serving users around the world benefit from sub-millisecond reads and writes in each region without custom replication code.
-
Storage Tiering & Cost Control
Redis Open Source:
All data lives in RAM. You can attempt to extend capacity with OS-level swapping or external storage layers, but those approaches add latency and operational complexity, and DRAM remains expensive at scale.
Redis Enterprise:
Enterprise provides auto-tiering that blends DRAM with fast SSD or persistent memory. Frequently accessed keys stay in memory while colder data moves to flash storage automatically. This lets you keep far larger datasets at a lower cost while maintaining near-memory performance for hot data.
-
Modules & Feature Parity
Redis Open Source / Redis Stack:
Popular modules such as RediSearch, RedisJSON, RedisTimeSeries, RedisBloom, and RedisGraph are available in the community edition. However, their licenses have evolved (AGPL, SSPL, RSAL), so organizations need to review the terms before deploying them in commercial products.
Redis Enterprise:
Enterprise ships with the same core modules but adds performance optimizations, deeper monitoring, and multi-tenant management. Some modules are enhanced or tested specifically for the Enterprise environment, and commercial licensing simplifies legal compliance for production use.
- Licensing, Support & Compliance
Redis Open Source:
Recent versions use a tri-license model (AGPLv3, SSPL, or RSAL, depending on the component). This works well if your team can operate and maintain Redis independently and you’re comfortable meeting the obligations of those licenses. Regardless of edition, ongoing Redis maintenance – including eviction policy tuning, connection limit configuration, and replication health checks – is essential to sustaining production-grade performance.
Redis Enterprise:
Enterprise is sold under a commercial subscription. Along with the software, you get 24/7 vendor support, guaranteed SLAs, security patches, and help with regulatory requirements such as SOC 2 or HIPAA. For organizations running business-critical or regulated workloads, this level of support and legal clarity is often worth the cost.
Redis Open Source vs Redis Enterprise: Which should you choose?
Before committing to either edition, it helps to understand why businesses need Redis services – from caching and session management to pub/sub real-time messaging – to validate which deployment model fits your actual workloads.
Choose Redis Open Source if:
- You need a fast cache or a small-to-medium primary store.
- You want full control of deployment and lower upfront costs.
- Your team can manage scaling, HA, backups, and module compatibility.
- Your licensing and deployment model fit OSS terms.
Choose Redis Enterprise if:
- You need global Active-Active writes (multi-region, low latency).
- You must run very large datasets cost-effectively (DRAM + Flash tiering).
- You require predictable SLAs, vendor support, or enterprise security/compliance features.
- You want simpler operations at a large scale (automated rebalancing, faster failover, management tooling).
Conclusion: Choosing Between Redis OSS and Redis Enterprise
Redis Open Source is ideal for teams that value full control, open licensing, and have the in-house expertise to manage scaling, backups, and high availability themselves. Redis Enterprise, on the other hand, shines when your workloads demand global scale, predictable high availability, and lower total cost of ownership at large data volumes. Whether you are running Redis OSS or planning an upgrade to Redis Enterprise, Ksolves offers expert consulting, implementation, and 24/7 Redis Enterprise support services. Our team helps with cluster design, performance tuning, seamless migration, and ongoing maintenance so you can focus on building applications while we ensure Redis runs at peak performance.
![]()
Frequently Asked Questions
What is the main difference between Redis Open Source and Redis Enterprise?
Redis Open Source (Redis OSS) is a community-maintained, in-memory data store that is free to deploy and manage. Redis Enterprise is Redis Ltd.’s commercial offering that adds enterprise-grade capabilities — including Active-Active geo-distribution with CRDTs, auto-tiering of DRAM and SSD, faster automated failover, and 24/7 SLA-backed support — on top of the same Redis API. The core difference comes down to operational complexity and scale: OSS requires teams to manage clustering, HA, and modules themselves, while Enterprise handles these automatically.
Is Redis Open Source still a good choice for production workloads in 2026?
Yes, Redis OSS remains an excellent choice for production workloads where datasets fit comfortably in DRAM, the team has in-house Redis expertise, and there is no need for multi-region Active-Active writes. It is particularly well-suited to caching layers, session stores, leaderboards, and message queues at small to medium scale. For organizations that can manage scaling, backups, and HA independently, Redis OSS offers full control with no licensing cost. The main risk is operational burden growing as usage scales.
When should a company upgrade from Redis Open Source to Redis Enterprise?
An upgrade to Redis Enterprise makes sense when a company outgrows what Redis OSS can manage without heavy engineering investment. Common triggers include the need for low-latency writes across multiple geographic regions (Active-Active), datasets that are too large and costly to keep entirely in DRAM (auto-tiering to flash), stricter uptime SLAs than self-managed infrastructure can guarantee, or regulated workloads requiring SOC 2 or HIPAA compliance and vendor support. Ksolves helps teams assess readiness and execute Redis migrations with zero downtime.
What does Active-Active replication in Redis Enterprise actually mean?
Active-Active replication in Redis Enterprise allows multiple Redis instances in different geographic regions to accept write operations simultaneously. Unlike traditional primary-replica setups, there is no single write primary — all regions are peers. Conflict resolution is handled automatically using conflict-free replicated data types (CRDTs), so applications serving users across regions get sub-millisecond read and write latency in each location without custom conflict handling code. Redis OSS does not support this pattern natively.
How does Redis Enterprise’s auto-tiering reduce infrastructure costs?
Redis Enterprise’s auto-tiering automatically moves frequently accessed data to DRAM while less-accessed data is stored on fast SSD or persistent memory. This enables teams to maintain very large Redis datasets at a fraction of the cost of keeping everything in RAM, since DRAM is significantly more expensive per gigabyte than flash storage. The performance impact is minimal because hot keys stay in memory and cold data is fetched from flash at near-memory speeds.
Does Redis Open Source support high availability and failover?
Yes. Redis OSS supports high availability through Redis Sentinel (for standalone or primary-replica setups) and Redis Cluster (for sharded, horizontally scaled deployments). A typical HA configuration runs one primary and two replicas to avoid split-brain scenarios. Redis Enterprise improves on this with cluster-level quorum, faster automated detection, and recovery typically within a few seconds using only two replicas.
Can Ksolves help migrate from Redis Open Source to Redis Enterprise?
Yes. Ksolves provides end-to-end Redis migration services, covering cluster architecture assessment, data migration with minimal downtime, configuration translation, and post-migration performance tuning. Ksolves also supports migrations to managed Redis services such as AWS ElastiCache.
Have questions about which Redis edition fits your infrastructure? Contact our team for a free consultation.















AUTHOR
Big Data
Anil Kushwaha, Technology Head at Ksolves, is an expert in Big Data. With over 11 years at Ksolves, he has been pivotal in driving innovative, high-volume data solutions with technologies like Nifi, Cassandra, Spark, Hadoop, etc. Passionate about advancing tech, he ensures smooth data warehousing for client success through tailored, cutting-edge strategies.
Share with