

Integrating Apache Kafka with Apache Flink
Apache Flink
5 MIN READ
June 9, 2026
![]()

Apache Kafka has become the backbone of modern event-driven architectures. It captures every transaction, click, sensor reading, and state change your systems produce, stores it durably, and delivers it to any number of consumers in real time. But Kafka is a transport layer. It does not compute.
Apache Flink is the computation layer that turns a raw event stream into business value. Where Kafka excels at high-throughput, fault-tolerant event transport, Flink excels at stateful, low-latency stream processing. It joins streams, detects patterns across time windows, maintains running aggregations, and routes enriched events to downstream systems with sub-100ms latency and exactly-once correctness.
This Flink Kafka integration guide covers everything you need to build a production-grade pipeline. From connector configuration and watermark strategy to exactly-once semantics, error handling, performance tuning, and Kubernetes deployment, each section includes working Java code and the operational detail that separates a prototype from a system your team can trust at 3 AM.
Why Kafka and Flink Are Stronger Together Than Either Is Alone
Kafka is a distributed commit log. Producers write events to partitioned topics across a broker cluster. Consumers read at their own pace, tracking position with a numeric offset. Events are retained for hours, days, or indefinitely. This model delivers three properties that stream processing depends on.
- Decoupling: A payment service writes to a topic. A fraud detection job, a reporting job, and an audit job all consume it independently, at different speeds, without interfering with each other.
- Durability: Events are written to disk and replicated before the producer receives an acknowledgement. An acknowledged event survives broker failures.
- Replayability: When a Flink job restarts after a failure, it resets its read position to the last checkpointed offset and replays from there. Recovery is deterministic, not arbitrary.
Flink: The Stateful Processing Layer
Flink brings stateful stream processing with managed fault tolerance. Rolling aggregates, session windows, and join buffers all live inside Flink operators, backed by periodic checkpoints in durable storage.
On failure, Flink restores operator state from the last checkpoint and rewinds the Kafka offset to match. Processing resumes exactly where it left off, with no data loss and no duplicates. That coordination between Flink state and Kafka offsets is what makes the two systems stronger together than either is alone.
Kafka Streams vs Apache Flink: Choosing the Right Tool
Both Kafka Streams vs Apache Flink integration is a question teams face early when evaluating real-time architectures. Both tools process event streams, but they serve different use cases with very different operational trade-offs.
Kafka Streams is a lightweight Java library that runs inside your application process. It requires no separate cluster, integrates naturally with existing Kafka deployments, and works well for stateful transformations, aggregations, and joins scoped to a single Kafka cluster. It is the right choice when your processing logic is straightforward and you want minimal operational overhead.
Apache Flink is a distributed processing framework that runs as a separate cluster. It is the right choice when you need exactly-once semantics across multiple sinks, complex event processing across large time windows, stateful processing at hundreds of gigabytes of state per TaskManager, joining streams from sources beyond Kafka, or millisecond-latency processing under heavy backpressure. Flink also provides richer watermark handling, native support for broadcast state, and a more expressive API for complex pipeline topologies.
In short: use Kafka Streams for simple, self-contained Kafka-to-Kafka transformations. Use Flink when your pipeline has complex state, multiple sources or sinks, or strict correctness requirements at scale.
Architecture Overview
A production Kafka-Flink pipeline is built around four logical layers. Producers push events into Kafka, which handles durable transport and partitioned storage. Flink reads from Kafka, applies stateful computation, and writes results to downstream consumers such as databases, dashboards, or other Kafka topics. The checkpoint store sits beneath all four layers, binding Kafka source offsets to Flink operator state snapshots so that recovery after any failure is deterministic and bounded.
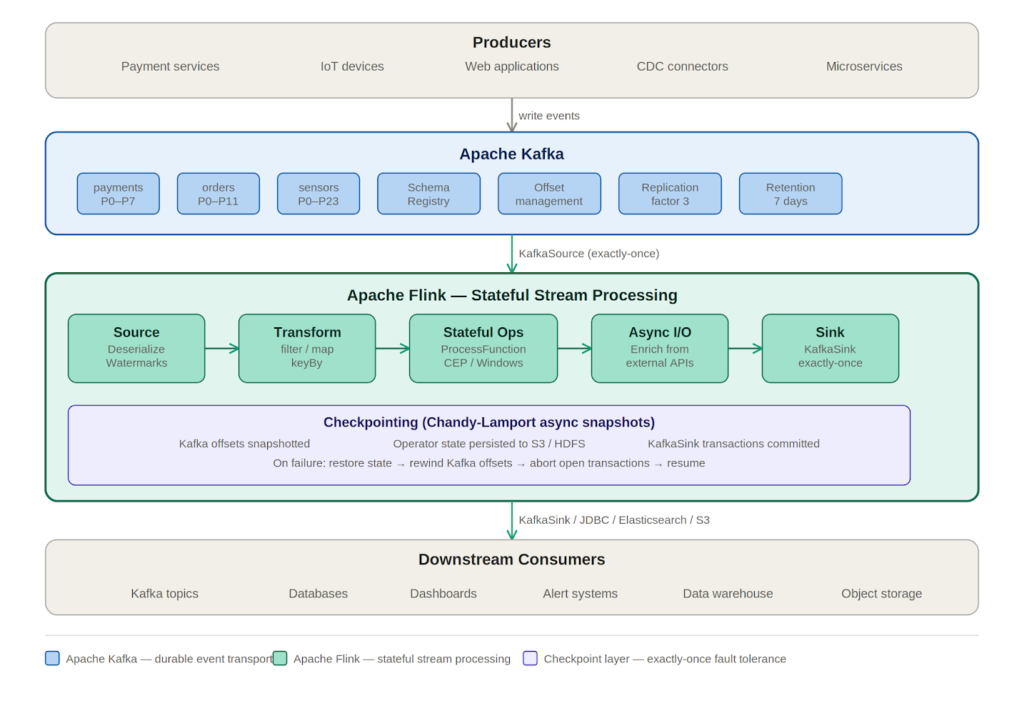
Apache Flink Kafka Connector Setup
The Apache Flink Kafka connector setup begins with adding the connector as a separate Maven dependency. Pin the version to match your Flink runtime exactly
| <dependency>
<groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka</artifactId> <version>3.2.0-1.19</version> </dependency> |
Reading from Kafka: KafkaSource
The KafkaSource API (introduced in Flink 1.14) replaced the legacy FlinkKafkaConsumer. It provides cleaner APIs, better support for dynamic partition discovery, and tighter integration with the Source / SplitEnumerator architecture.
Basic consumer with watermark strategy
Java-KafkaSource with event-time watermarks:
| KafkaSource<OrderEvent> source = KafkaSource.<OrderEvent>builder()
.setBootstrapServers(“kafka-broker-1:9092,kafka-broker-2:9092”) .setTopics(“orders.placed”) .setGroupId(“flink-order-processor”) .setStartingOffsets(OffsetsInitializer.committedOffsets( OffsetResetStrategy.EARLIEST)) .setValueOnlyDeserializer(new OrderEventDeserializationSchema()) .build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<OrderEvent> orders = env.fromSource( source, WatermarkStrategy .<OrderEvent>forBoundedOutOfOrderness(Duration.ofSeconds(10)) .withTimestampAssigner( (event, ts) -> event.getOrderTimestamp()), “order-source”); |
Three decisions in this snippet deserve explanation. Starting offsets: committedOffsets(EARLIEST) resumes from the last committed offset if one exists, and falls back to earliest for a fresh start. Watermark strategy: forBoundedOutOfOrderness(10 seconds) expects events arriving up to 10 seconds out of order and advances the event-time watermark accordingly. Consumer group: required for monitoring consumer lag in Kafka tooling.
Dynamic partition discovery
When your Kafka topic gains new partitions after the Flink job starts, Flink needs to discover and start reading those new partitions automatically.
Java, topic pattern with automatic partition discovery:
| KafkaSource<SensorReading> source = KafkaSource.<SensorReading>builder()
.setBootstrapServers(“kafka:9092”) .setTopicPattern(Pattern.compile(“sensors\\.zone\\.[0-9]+”)) .setGroupId(“flink-sensor-aggregator”) .setStartingOffsets(OffsetsInitializer.committedOffsets( OffsetResetStrategy.LATEST)) // Check for new partitions every 30 seconds .setProperty( KafkaSourceOptions.PARTITION_DISCOVERY_INTERVAL_MS.key(), “30000”) .setValueOnlyDeserializer(new SensorReadingSchema()) .build(); |
Writing to Kafka: KafkaSink
The KafkaSink API provides configurable delivery guarantees. Exactly-once delivery requires Kafka transactions — downstream consumers must set isolation.level=read_committed to see only committed data.
Java — exactly-once KafkaSink (required for financial pipelines):
| KafkaSink<EnrichedOrderEvent> sink = KafkaSink.<EnrichedOrderEvent>builder()
.setBootstrapServers(“kafka:9092”) .setRecordSerializer( KafkaRecordSerializationSchema.builder() .setTopic(“orders.enriched”) .setValueSerializationSchema( new EnrichedOrderEventSerializationSchema()) .build()) .setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE) // Prefix must be unique per Flink job .setTransactionalIdPrefix(“order-enrichment-job”) .build();
// Checkpointing is required for exactly-once env.enableCheckpointing(60_000); env.getCheckpointConfig().setCheckpointingMode( CheckpointingMode.EXACTLY_ONCE); |
The transactional ID prefix must be unique to each Flink job. If two jobs share a prefix, their Kafka transactions will conflict. Version your prefixes: fraud-detector-v1, fraud-detector-v2.
Exactly-Once Semantics: What It Means and How It Works
Exactly-once in a Kafka-Flink pipeline is a two-part contract, covering the source and the sink separately.
On the source side, Flink’s checkpointing records the Kafka offset for each partition at the moment a checkpoint snapshot is taken. If the job fails, Flink resets each partition’s read position to those checkpointed offsets and replays any events that were consumed after the last successful checkpoint completed.
On the sink side, Flink uses Kafka’s transactional producer API. When a checkpoint begins, the sink opens a Kafka transaction and writes all events processed during that interval into it. When the JobManager confirms the checkpoint is complete, the sink commits the transaction. If the job fails before that confirmation arrives, the transaction is aborted and those events are reprocessed from the checkpointed offset on restart.
The result is a clean guarantee: every event from the source is processed exactly once, and every event written to the sink appears exactly once. Three conditions must hold for this guarantee to be valid. Checkpointing must be enabled on the Flink environment. The sink must be configured with EXACTLY_ONCE delivery guarantee. And all downstream Kafka consumers must set isolation level to read_committed, otherwise they read data from transactions that may still be aborted.
How to integrate Apache Kafka with Apache Flink
The following patterns demonstrate how to integrate Apache Kafka with Apache Flink across two of the most common production scenarios teams encounter.
-
Building a Payment Fraud Detection Pipeline
This pattern walks through a complete Kafka-to-Kafka fraud detection pipeline. Raw payment events are consumed from an input topic, enriched with merchant risk scores via async lookup, and analysed for suspicious per-card patterns using stateful processing. Flagged transactions are written as alerts to a dedicated output topic with exactly-once delivery guaranteed end-to-end.
Java – full fraud detection job with async enrichment and exactly-once sink:
| StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(30_000); env.getCheckpointConfig().setCheckpointingMode( CheckpointingMode.EXACTLY_ONCE); env.getCheckpointConfig().setMinPauseBetweenCheckpoints(10_000); env.getCheckpointConfig().setCheckpointTimeout(120_000);
// Source KafkaSource<PaymentEvent> source = KafkaSource.<PaymentEvent>builder() .setBootstrapServers(“kafka:9092”) .setTopics(“payments.raw”) .setGroupId(“flink-fraud-detector”) .setStartingOffsets(OffsetsInitializer.committedOffsets( OffsetResetStrategy.LATEST)) .setValueOnlyDeserializer(new PaymentEventSchema()) .build();
DataStream<PaymentEvent> payments = env.fromSource( source, WatermarkStrategy .<PaymentEvent>forBoundedOutOfOrderness(Duration.ofSeconds(5)) .withTimestampAssigner( (p, ts) -> p.getTransactionTimestamp()), “payments-source”);
// Async enrichment: fetch merchant risk score DataStream<EnrichedPayment> enriched = AsyncDataStream .unorderedWait( payments, new MerchantRiskEnricher(merchantRiskServiceUrl), 2, TimeUnit.SECONDS, 500);
// Fraud detection: stateful per-card analysis DataStream<FraudAlert> alerts = enriched .keyBy(EnrichedPayment::getCardId) .process(new FraudPatternDetector());
// Sink KafkaSink<FraudAlert> sink = KafkaSink.<FraudAlert>builder() .setBootstrapServers(“kafka:9092”) .setRecordSerializer( KafkaRecordSerializationSchema.builder() .setTopic(“fraud.alerts”) .setValueSerializationSchema(new FraudAlertSchema()) .build()) .setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE) .setTransactionalIdPrefix(“fraud-detector-v2”) .build();
alerts.sinkTo(sink); env.execute(“Payment Fraud Detector”); |
- Stream Enrichment with Broadcast Join
A common production pattern is joining a high-volume event stream against a slower-moving reference stream. The broadcast state pattern solves this efficiently. Reference data, such as product catalogues and risk tables, is pushed to all Flink task managers once, so every enrichment lookup reads from local memory with zero network overhead.
Java – order stream joined against broadcast product catalogue:
| DataStream<OrderEvent> orders = env.fromSource(
orderSource, WatermarkStrategy .<OrderEvent>forBoundedOutOfOrderness(Duration.ofSeconds(5)) .withTimestampAssigner((o, ts) -> o.getOrderTimestamp()), “orders-source”);
DataStream<ProductUpdate> catalogue = env.fromSource( catalogueSource, WatermarkStrategy .<ProductUpdate>forBoundedOutOfOrderness(Duration.ofSeconds(30)) .withTimestampAssigner((p, ts) -> p.getUpdateTimestamp()), “catalogue-source”);
MapStateDescriptor<String, ProductUpdate> catalogueState = new MapStateDescriptor<>( “catalogue-state”, String.class, ProductUpdate.class);
BroadcastStream<ProductUpdate> broadcastCatalogue = catalogue.broadcast(catalogueState);
DataStream<EnrichedOrder> enrichedOrders = orders .connect(broadcastCatalogue) .process(new OrderCatalogueEnricher(catalogueState)); |
Checkpointing and Fault Tolerance in Production
Checkpointing is the mechanism that gives Kafka-Flink pipelines their reliability. Without it, a job failure means reprocessing from an arbitrary point in Kafka history. With it, recovery is deterministic and bounded.
Java – recommended production checkpoint configuration:
| CheckpointConfig cp = env.getCheckpointConfig();
env.enableCheckpointing(60_000); cp.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); cp.setMinPauseBetweenCheckpoints(20_000); cp.setCheckpointTimeout(180_000); cp.setMaxConcurrentCheckpoints(1); cp.setExternalizedCheckpointCleanup( ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.setStateBackend(new EmbeddedRocksDBStateBackend()); env.getCheckpointConfig().setCheckpointStorage( “s3://your-bucket/flink-checkpoints/fraud-detector/”); |
RocksDB vs In-Memory State Backend
For most production pipelines, RocksDB is the right choice. In-memory state is faster but is strictly bounded by the executor heap size, making it unsuitable for pipelines with large or growing state. RocksDB stores state on local disk, manages its own off-heap memory, and supports state sizes in the hundreds of gigabytes per TaskManager without impacting the JVM heap.
Error Handling and Dead Letter Queues
Production pipelines encounter malformed messages, unexpected nulls, and schema mismatches. Route unparseable events to a dead letter topic rather than failing the job.
Java-side output dead letter queue pattern:
| OutputTag<DeserializationError> deadLetterTag =
new OutputTag<>(“dead-letter”){};
SingleOutputStreamOperator<OrderEvent> parsed = rawMessages .process(new ProcessFunction<byte[], OrderEvent>() { @Override public void processElement( byte[] raw, Context ctx, Collector<OrderEvent> out) { try { out.collect(MAPPER.readValue(raw, OrderEvent.class)); } catch (Exception e) { ctx.output(deadLetterTag, new DeserializationError( raw, e.getMessage(), Instant.now().toEpochMilli())); } } });
// Main stream proceeds normally DataStream<OrderEvent> validOrders = parsed;
// Malformed events routed to dead letter topic DataStream<DeserializationError> deadLetters = parsed.getSideOutput(deadLetterTag); deadLetters.sinkTo(deadLetterKafkaSink); |
Schema Registry Integration
The code examples in this guide use plain byte array deserialization for clarity. Production pipelines almost always use a schema registry Confluent Schema Registry or Apicurio, with Avro or Protobuf serialization.
KafkaSource<GenericRecord> source = KafkaSource.<GenericRecord>builder()
.setBootstrapServers(“kafka:9092”)
.setTopics(“orders.placed”)
.setGroupId(“flink-order-processor”)
.setStartingOffsets(OffsetsInitializer.committedOffsets(
OffsetResetStrategy.EARLIEST))
.setValueOnlyDeserializer(
ConfluentRegistryAvroDeserializationSchema.forGeneric(
schema, “https://schema-registry:8081”))
.build();
Set schema compatibility to BACKWARD mode on your registry. This ensures the Flink job can read messages written with older schema versions without a job restart. For breaking schema changes, take a savepoint, update the deserializer, and redeploy from the savepoint.
Deploying on Kubernetes
Application mode is the recommended deployment for production Flink jobs. Each job gets its own JobManager and TaskManager pods, no shared cluster, so one job’s resource usage cannot starve another’s. The upgradeMode: savepoint setting ensures zero state loss during deployments.
YAML – Flink Application Mode on Kubernetes:
| apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment metadata: name: fraud-detector namespace: streaming spec: image: your-registry/fraud-detector:v2.1.0 flinkVersion: v1_19 flinkConfiguration: taskmanager.numberOfTaskSlots: “4” state.backend: rocksdb state.checkpoints.dir: s3://your-bucket/flink-checkpoints/fraud-detector execution.checkpointing.interval: “60000” execution.checkpointing.mode: EXACTLY_ONCE rest.flamegraph.enabled: “true” jobManager: resource: memory: “2048m” cpu: 1 taskManager: resource: memory: “4096m” cpu: 2 replicas: 6 job: jarURI: local:///opt/flink/usrlib/fraud-detector.jar parallelism: 24 upgradeMode: savepoint |
Six Production Pitfalls That Break Kafka-Flink Pipelines
- Parallelism Does Not Match Kafka Partition Count
A Flink source task reads at most one Kafka partition. If parallelism is lower than the partition count, some partitions are assigned to the same task, limiting throughput. If parallelism exceeds the partition count, some tasks sit idle. Always set env.setParallelism() to a multiple of the source topic’s partition count.
- Checkpointing Not Enabled Before Exactly-Once Sink
Delivery Guarantee.EXACTLY_ONCE on KafkaSink requires checkpointing to be active on the Flink environment. Without it, Flink throws a configuration exception at startup. Call env.enableCheckpointing() before registering the sink.
- Checkpoint Interval Too Aggressive for State Size
A 5-second checkpoint interval on a job with large RocksDB state spends more time checkpointing than processing. Start at 60 seconds and monitor checkpoint duration metrics. If checkpoints consistently take longer than 30 percent of the interval, increase it.
- Reusing Transactional ID Prefix Across Job Versions
When a new job version shares the same transactional ID prefix as the previous deployment, it aborts the old job’s open Kafka transactions. This corrupts in-flight data. Version your prefixes on every deployment: fraud-detector-v1, fraud-detector-v2.
- Downstream Consumers Not Reading Committed Data Only
Configuring DeliveryGuarantee.EXACTLY_ONCE on the sink is only half the contract. If downstream Kafka consumers do not set isolation.level=read_committed, they read events from transactions that may still be aborted. Every consumer of an exactly-once topic must set this property explicitly.
- Insufficient TaskManager Memory for RocksDB
RocksDB manages its own off-heap memory outside the JVM heap. Without adequate allocation, it spills excessively to disk and degrades throughput. Set taskmanager.memory.managed.fraction to at least 0.4 to give RocksDB 40 percent of total TaskManager memory as its managed memory budget.
How Ksolves Builds Kafka-Flink Pipelines
At Ksolves, Kafka-Flink integration is one of the most requested architectures our Big Data division designs and delivers. We have built production pipelines across financial services, e-commerce, IoT, and logistics. Every engagement is scoped to what your pipeline actually needs.
Here is what we bring to every project:
- Architecture Design: Partition strategy, watermark configuration, state backend selection, and checkpoint tuning based on your throughput and latency requirements.
- Pipeline Development: Production Java Flink jobs covering deserialization, async enrichment, windowing, and CEP patterns with full test coverage using Flink MiniCluster.
- Exactly-Once Implementation: Full source-to-sink transactional boundary configuration, downstream consumer isolation, and transactional ID management across deployments.
- Schema Registry Integration: Avro or Protobuf serialization with Confluent Schema Registry or Apicurio, including schema evolution strategies that handle changes without pipeline downtime.
- Kubernetes Deployment: Flink native operator in application mode, savepoint-based upgrade workflows, and right-sized resource configuration for your workload.
- Observability: Prometheus metrics and Grafana dashboards covering consumer lag, checkpoint health, backpressure, and watermark progress.
- Performance Tuning: Parallelism alignment, RocksDB memory tuning, async I/O configuration, and backpressure root cause analysis.
Want to discuss your streaming architecture? Get in touch with the Ksolves Big Data team
Conclusion
Kafka and Flink are the two components most engineering teams reach for when they need to process data in real time with strong correctness guarantees. Kafka captures and durably stores every event your business generates. Flink processes those events with millisecond latency, managed state, and exactly-once semantics.
The KafkaSource and KafkaSink connectors handle offset management, partition discovery, and transactional delivery. Flink’s checkpointing mechanism ties source offsets to operator state snapshots, making recovery after any failure deterministic and bounded.
The patterns covered in this guide, including fraud detection, broadcast join enrichment, and windowed aggregation, represent the majority of what teams build on this stack. The operational decisions, including parallelism alignment, checkpoint tuning, RocksDB memory configuration, dead letter queue routing, and Kubernetes deployment, are what separate a working prototype from a pipeline your team can rely on in production.
If you are building a Kafka-Flink pipeline and want a team that has done it across financial services, e-commerce, IoT, and logistics, get in touch with the Ksolves Big Data division.
![]()
Frequently Asked Questions
What is the difference between Kafka and Flink?
Apache Kafka is a distributed commit log built for durable, high-throughput event transport, while Apache Flink is a stateful stream processing engine that computes over the data Kafka carries. Kafka stores and delivers events; Flink joins, aggregates, and enriches them with millisecond latency and exactly-once correctness.
What happens if checkpointing isn’t enabled before using Flink’s exactly-once Kafka sink?
Flink throws a configuration exception at startup, because DeliveryGuarantee.EXACTLY_ONCE on KafkaSink depends on active checkpointing to coordinate the Kafka transaction boundaries. Without checkpointing enabled first via env.enableCheckpointing(), the exactly-once guarantee has nothing to anchor its commit points to.
How do I achieve exactly-once processing in a Kafka-Flink pipeline?
Exactly-once processing requires three things together: checkpointing enabled on the Flink environment, the KafkaSink configured with EXACTLY_ONCE delivery guarantee, and every downstream Kafka consumer set to isolation.level=read_committed. Flink then ties source offsets to sink transactions so each event is processed and written exactly once.
Should I use Kafka Streams or Apache Flink for stream processing?
Kafka Streams fits simple, self-contained Kafka-to-Kafka transformations that don’t need a separate cluster to manage. Apache Flink is the better choice once you need exactly-once semantics across multiple sinks, joins from sources beyond Kafka, or stateful processing at hundreds of gigabytes per TaskManager.
When should a team move from Kafka Streams to Apache Flink?
Teams typically move to Flink once processing logic outgrows a single Kafka cluster — for example, when a pipeline needs to join streams from multiple sources, handle complex event patterns across large time windows, or guarantee exactly-once delivery to several downstream sinks at once.
Who can help build a production-grade Kafka-Flink pipeline?
Ksolves’ Big Data division designs and delivers Kafka-Flink architectures for financial services, e-commerce, IoT, and logistics clients, covering partition strategy, watermark configuration, exactly-once implementation, and Kubernetes deployment end to end.
How long does it take to build a production Kafka-Flink pipeline?
Timelines depend on state size, number of sinks, and correctness requirements, but most teams move from architecture design to a savepoint-ready Kubernetes deployment within several weeks when working with an experienced partner. Ksolves scopes each Kafka-Flink engagement to the pipeline’s actual throughput and latency needs rather than a fixed template.
Still have questions about your Kafka-Flink architecture? Contact our team.















AUTHOR
Apache Flink
Anil Kushwaha, Technology Head at Ksolves, is an expert in Big Data. With over 11 years at Ksolves, he has been pivotal in driving innovative, high-volume data solutions with technologies like Nifi, Cassandra, Spark, Hadoop, etc. Passionate about advancing tech, he ensures smooth data warehousing for client success through tailored, cutting-edge strategies.
Share with