

All About Trino: The Core Concept Explained
Big Data
5 MIN READ
May 26, 2026
![]()

The Trino query engine is one of the most important pieces of infrastructure in the modern data stack. Many organisations hold large volumes of structured and semi-structured data spread across Amazon S3, Google Cloud Storage, Apache Hive, Delta Lake, and dozens of relational databases. Trino allows teams to query all of that data using standard SQL without weeks of ETL work, without duplicating data into a separate system, and without re-training analysts on new tools.
Despite its growing adoption among data-forward enterprises, many business and technical leaders still have open questions about Trino. What exactly is it? How does the architecture work? Where does it fit compared to a cloud data warehouse? And what does it take to run it reliably in production? This guide answers all of those questions in plain language, with practical context for B2B decision-makers evaluating their data infrastructure options.
What Is Apache Trino?
Apache Trino is an open-source distributed SQL query engine designed to query large datasets across diverse data sources at interactive speed. It does not store data itself. Instead, it connects to external data sources through a pluggable connector framework and pushes computation across a cluster of worker nodes to return query results quickly.
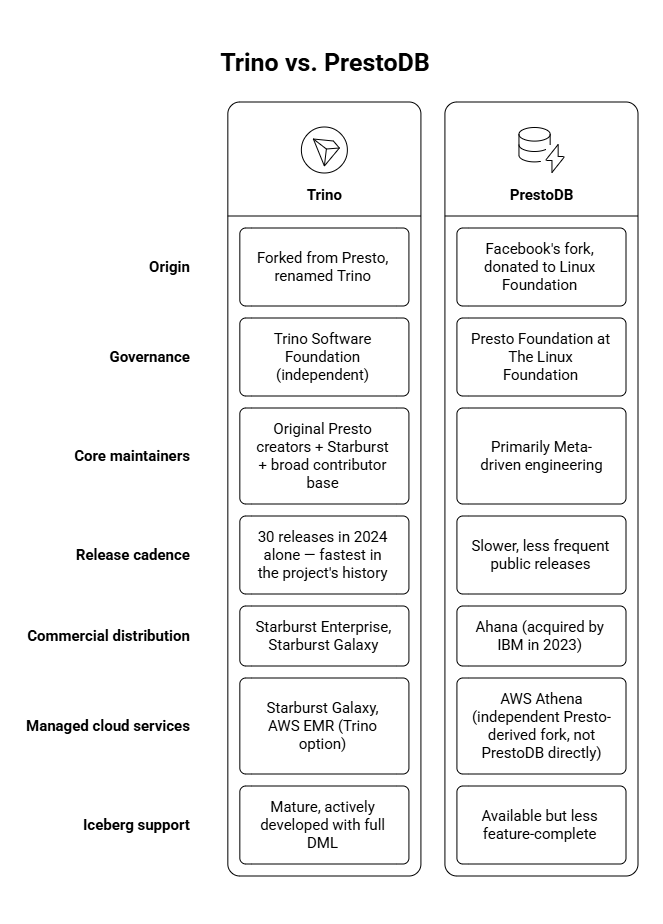
Trino was created at Facebook (now Meta) as a replacement for Hive queries that were too slow for interactive use. The project was open-sourced in 2013 under the name Presto. In 2019, the original creators of Presto left Meta and founded a separate project, renaming it Trino to distinguish the community-led direction from the Meta-internal fork. Today, Apache Trino is governed by the Trino Software Foundation and maintained by a broad open-source community.
Key characteristics of Apache Trino include:
- ANSI SQL compliance: Trino supports standard SQL, including complex joins, window functions, subqueries, and common table expressions (CTEs).
- Federated querying: A single query can span multiple data sources simultaneously.
- In-memory processing: Trino processes data in memory across worker nodes, avoiding intermediate disk writes wherever possible.
- Pluggable connectors: Native connectors exist for Hive Metastore, Apache Iceberg, Delta Lake, Apache Hudi, PostgreSQL, MySQL, Cassandra, Kafka, Elasticsearch, and more.
- No data movement required: Trino queries data in place, eliminating the need to copy data into a central warehouse before analyzing it.
Trino vs Presto: What Is the Difference?
The Trino and Presto naming situation confuses many practitioners. Here is an accurate breakdown of the current landscape:
How the Trino Distributed SQL Architecture Works?
Understanding the Trino distributed SQL architecture explains why it can process billions of rows far faster than batch-oriented engines like Apache Hive on MapReduce. Trino runs on a cluster of nodes with two distinct roles: a coordinator and one or more workers. All internal communication between the coordinator, workers, and clients happens over a REST API.
- Coordinator Node: Receives SQL queries from clients, parses them, plans the execution strategy, and distributes tasks to worker nodes. It is the control center of the cluster.
- Worker Nodes: Execute assigned tasks in parallel, fetch data from connectors, exchange intermediate results with each other, and stream final results back to the coordinator.
- Connectors: Plug-in interfaces that allow Trino to communicate with external data sources. Each connector implements Trino’s Service Provider Interface (SPI) for a specific system.
- Pipelined Execution: Data flows between stages in a streaming, in-memory pipeline. This avoids the disk I/O overhead of MapReduce and keeps query latency low even for complex multi-join workloads.
Because all intermediate data is processed in memory and streamed through the pipeline rather than written to disk, Trino achieves sub-second to minute-level query latency depending on data volume and cluster size. Scaling the cluster is straightforward: adding more worker nodes increases parallel processing capacity without any architectural changes.
What Is a Data Lakehouse and Why Does Trino Matter for It?
A data lakehouse is an architecture that combines the low-cost, scalable storage of a data lake with the structured querying, ACID compliance, and governance of a data warehouse. It uses open table formats, primarily Apache Iceberg, Delta Lake, and Apache Hudi, applied directly on top of object storage such as Amazon S3. This enables ACID transactions, schema evolution, and time-travel queries on raw storage without data duplication or migration into a separate system.
Trino is the query engine that makes this architecture practical at scale. It reads directly from object storage using these table formats, supports full ANSI SQL, and federates queries across the lakehouse and other connected systems simultaneously. Organisations that want to avoid the complexity of a pure data lake and the ongoing cost of a fully managed cloud warehouse are increasingly choosing data lakehouse solutions built on Trino as their default architecture.
Why Businesses Are Adopting Trino for Data Lakehouse Analytics
The data lakehouse paradigm has moved from an emerging concept to a mainstream enterprise architecture. Trino sits at the center of many of these deployments because it solves a specific and costly problem: how do you run fast analytical SQL queries at scale without copying data into an expensive proprietary warehouse? Here are the key features that make B2B businesses adopt Data Lakehouse Analytics.
- Federated Queries Across Data Silos: Trino can join data from a PostgreSQL operational database, an S3 data lake, and a Kafka stream in a single SQL query. This eliminates the need for complex ETL pipelines just to answer cross-system business questions.
- Interactive BI and Ad-Hoc Analytics: Tools like Apache Superset, Tableau, Metabase, and Power BI connect directly to Trino via standard JDBC and ODBC drivers. Analysts can write familiar SQL queries and receive results in seconds rather than hours.
- Cost-Efficient Petabyte-Scale Processing: By querying data directly in object storage without first loading it into a proprietary warehouse, organisations reduce storage duplication costs significantly. Trino’s separation of compute and storage also means you only pay for query compute when queries actually run, removing the always-on cost of managed warehouse services.
- Open Table Format Compatibility: Trino has native, production-grade support for Apache Iceberg, Delta Lake, and Apache Hudi. These table formats deliver ACID transactions, schema evolution, and time-travel queries directly on object storage, giving you warehouse-grade data quality without warehouse-grade cost.
- Multi-Cloud and Hybrid Deployments: Trino is cloud-agnostic by design. It runs identically on AWS, GCP, Azure, and on-premises Kubernetes clusters, giving enterprises the flexibility to operate across cloud environments without vendor lock-in.
What Does It Take to Run Trino in Production?
Running Trino reliably in production is more involved than standing up a development cluster. Four areas demand attention from every enterprise team before going live.
- Cluster Sizing. Node sizing directly determines query throughput and cost. Too few workers causes queue buildup; too many waste computing budget. Capacity planning must account for peak concurrency and data volume, with an auto-scaling strategy ready for demand spikes.
- Security and Access Control. Production clusters need LDAP or OAuth2 authentication, TLS across all communications, column-level and row-level access control, and full audit logging. Trino supports all of this natively via file-based rules, OPA integration, and the Apache Ranger plugin.
- Query Performance Tuning. Unoptimised queries are the top cause of runaway costs and slow response times. Partition pruning, cost-based optimizer (CBO) statistics, and proper join ordering can reduce execution time dramatically. Getting this right requires deep knowledge of Trino internals.
- Connector and Schema Management. Every connected data source needs its own catalog configuration, credentials, and schema registration. In multi-source environments, this overhead compounds quickly without structured governance.
Each of these challenges has a well-defined solution, but applying it correctly in a real production environment takes time and experience. That is exactly where Ksolves Trino support services can help you. Our certified Big Data engineers handle cluster sizing, security hardening, query tuning, and connector setup, so your team can focus on delivering analytics value rather than managing infrastructure. Talk to a Ksolves Trino expert today and get your production deployment right from day one.
Trino vs Cloud Data Warehouses: When Should You Choose Trino?
Trino is not a replacement for every use case that a cloud warehouse like Snowflake or BigQuery serves. However, for specific architectural needs, it is the stronger choice. The table below provides a practical decision framework for common scenarios.
| Scenario | Recommended Choice |
| You hold large volumes of data in S3, GCS, or ADLS and need SQL access | Trino |
| You need to query across multiple databases and data sources in one SQL statement | Trino |
| You want to avoid proprietary data formats and vendor lock-in | Trino |
| You need a fully managed SaaS analytics database with minimal operational overhead | Cloud Warehouse (Snowflake / BigQuery) |
| You are building a lakehouse on Apache Iceberg or Delta Lake and need ACID queries | Trino |
| You need to combine streaming and batch analytics in a single query layer | Trino with Apache Kafka connector |
Get Trino Support Services From Ksolves AI-Enabled Experts
Trino is a powerful technology, but deploying it correctly in production requires expertise that most internal data teams do not have on day one. Ksolves provides end-to-end Trino support services for B2B organisations building data lakehouse infrastructure across financial services, e-commerce, media, and logistics.
From initial architecture design through performance optimisation and 24/7 managed support, our certified AI-Enabled big data engineers use AI tools to accelerate cluster diagnostics, catch query anti-patterns early, and deliver faster time-to-value than traditional consulting engagements.
Conclusion
Trino is the right query engine for any organisation serious about building a modern data lakehouse. Its federated architecture, open table format support, and cloud-agnostic design give enterprise teams the SQL performance they need without proprietary lock-in or unnecessary data movement.
The distance between a working Trino cluster and a production-grade deployment is real. Ksolves closes that gap fast. With certified Trino engineers, AI-assisted diagnostics, and hands-on experience across industries, we help you go live confidently and scale without surprises. Contact Ksolves today to get started.
![]()















AUTHOR
Big Data
Anil Kushwaha, Technology Head at Ksolves, is an expert in Big Data. With over 11 years at Ksolves, he has been pivotal in driving innovative, high-volume data solutions with technologies like Nifi, Cassandra, Spark, Hadoop, etc. Passionate about advancing tech, he ensures smooth data warehousing for client success through tailored, cutting-edge strategies.
Share with